group improve n
1 Control no 12
2 Control yes 3
3 Treatment no 5
4 Treatment yes 10
Hypothesis Testing III
Megan Ayers
Math 141 | Spring 2026
Wednesday, Week 8
Exploratory Data Analysis
Two-Sided Hypothesis Test
Compute observed test statistic:
# A tibble: 2 × 2
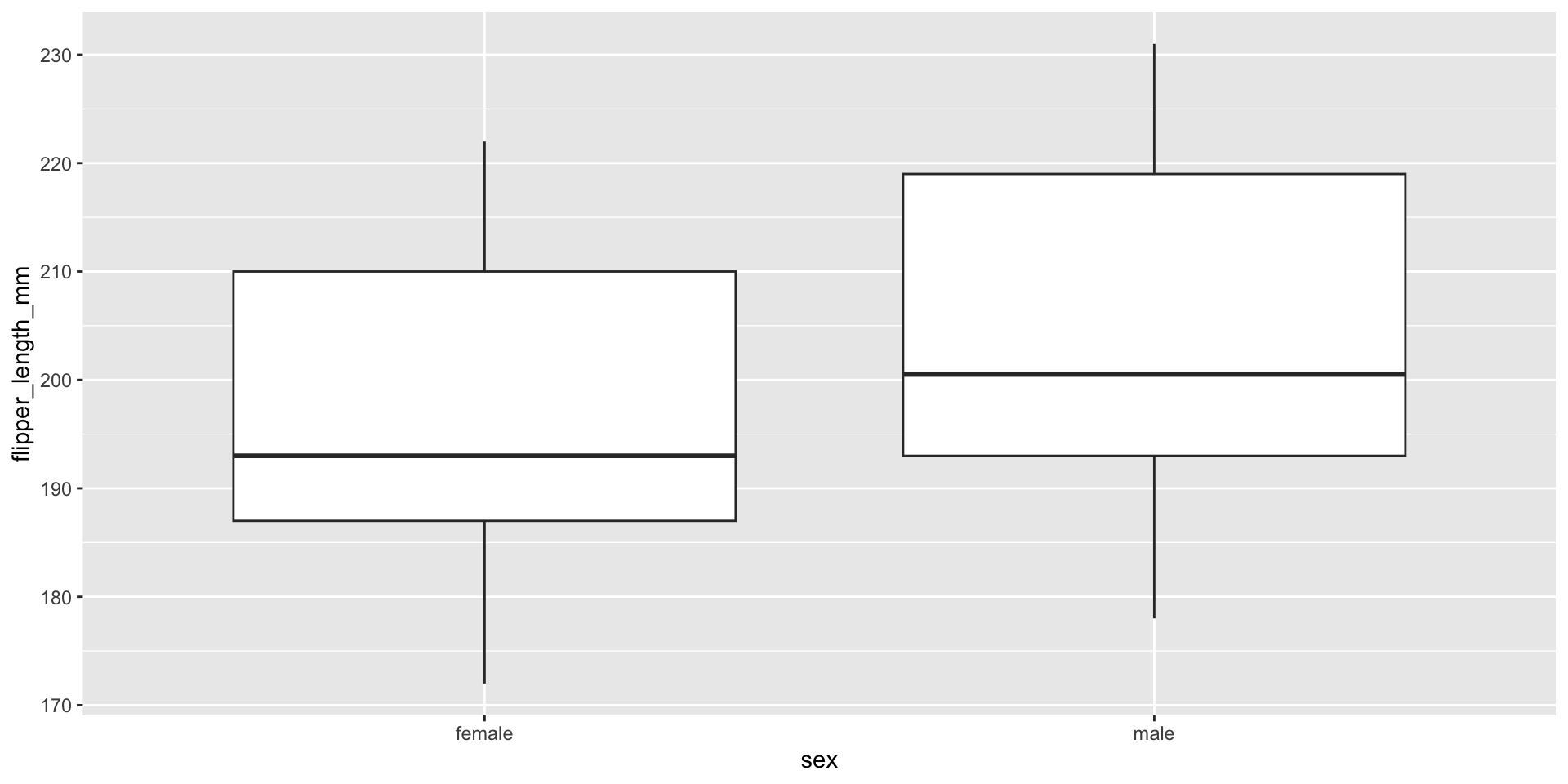
sex avg_length
<fct> <dbl>
1 female 197.
2 male 205.\(\rightarrow\) Our test statistic is: 7.1424
Generate the null distribution by simulating many data sets where gender is shuffled (code not shown for brevity), and visualize null sampling distribution compared to our test statistic:
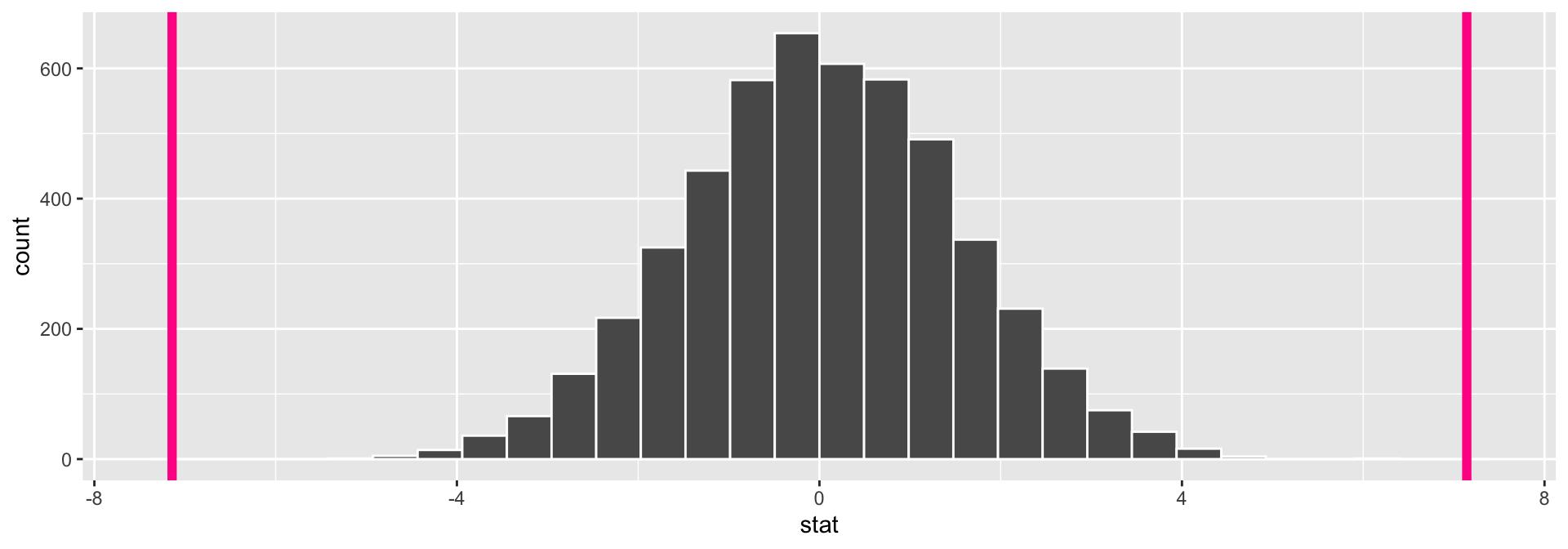
Q: Guesses for p-value?
Two-Sided Hypothesis Test
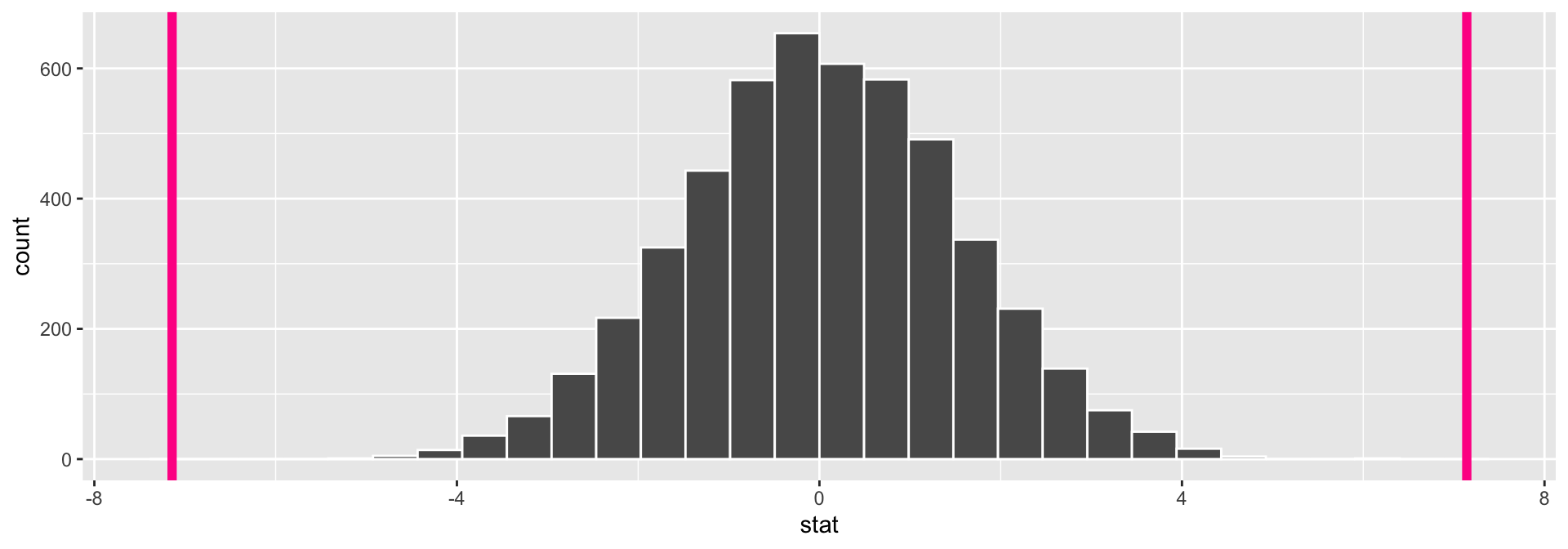
Calculate the p-value for a two-sided test:
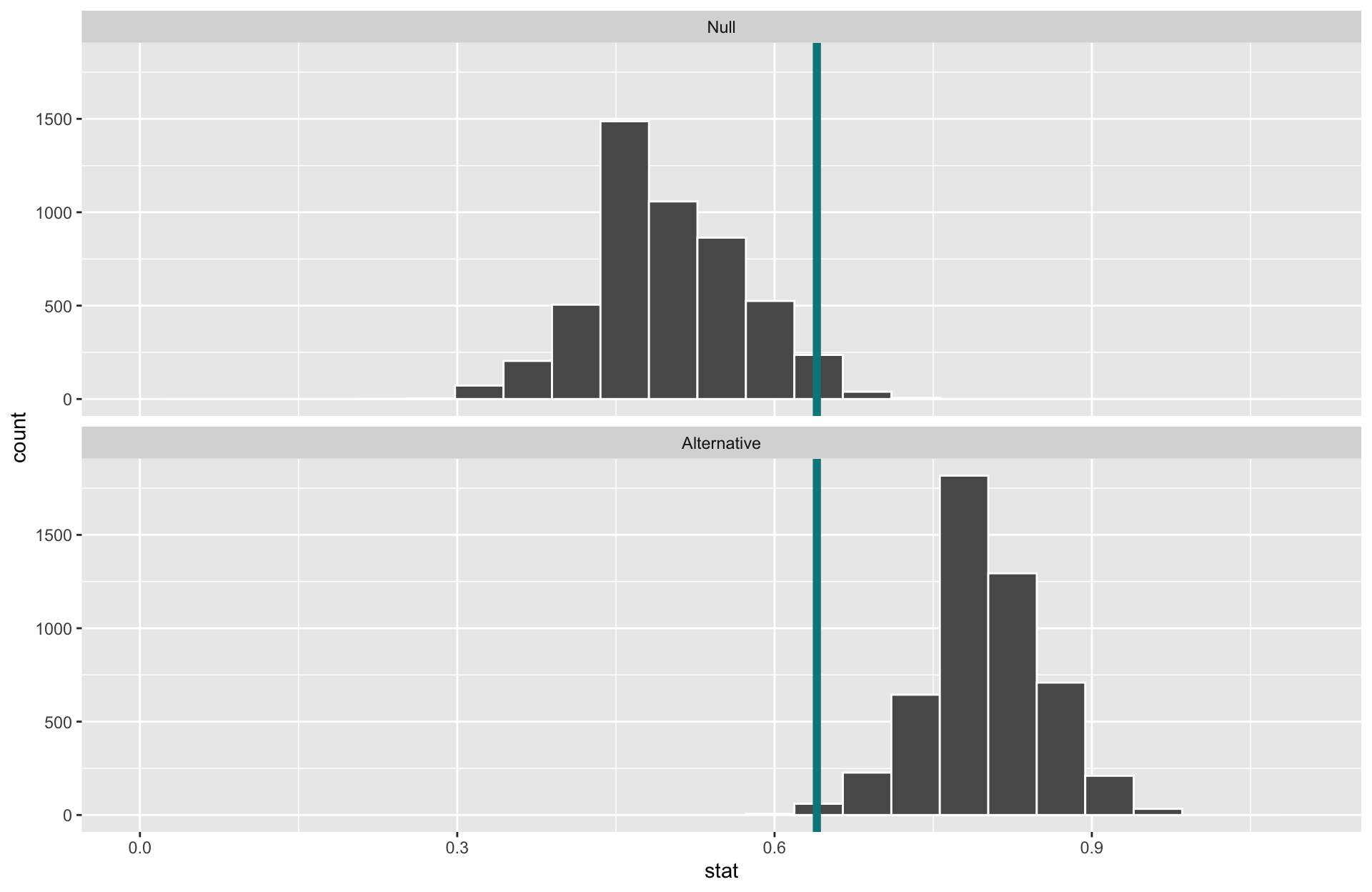
[1] 0Interpretation of \(p\)-value: If the mean flipper length does not differ by sex in the population, the probability of observing a difference in the sample means of at least 7.14 mm (in magnitude) is equal to 0.
Conclusion: These data represent evidence that flipper length does vary by sex.
Hypothesis Testing: Decisions, Decisions
Open Question: How do I select \(\alpha\)?
Will depend on the convention in your field (0.05 is common).
Want a small \(\alpha\) and a small \(\beta\). But they are related.
- The smaller \(\alpha\) is the larger \(\beta\) will be.
Q: Can’t easily compute \(\beta\) (probability of failing to reject a false null hypothesis). Why?
Important related concept:
- Power = probability reject \(H_0\) when the alternative is true.
- Q: Why is power important when designing an experiment?

Example
Suppose we want to test whether someone can detect AI-generated text from real text. We show a participant 10 short passages that are each either written by a human or an AI agent, and ask them to identify which are written by AI. Suppose the participant’s true (long-run) detection rate is 70%.
\(H_0\):
\(H_a\):
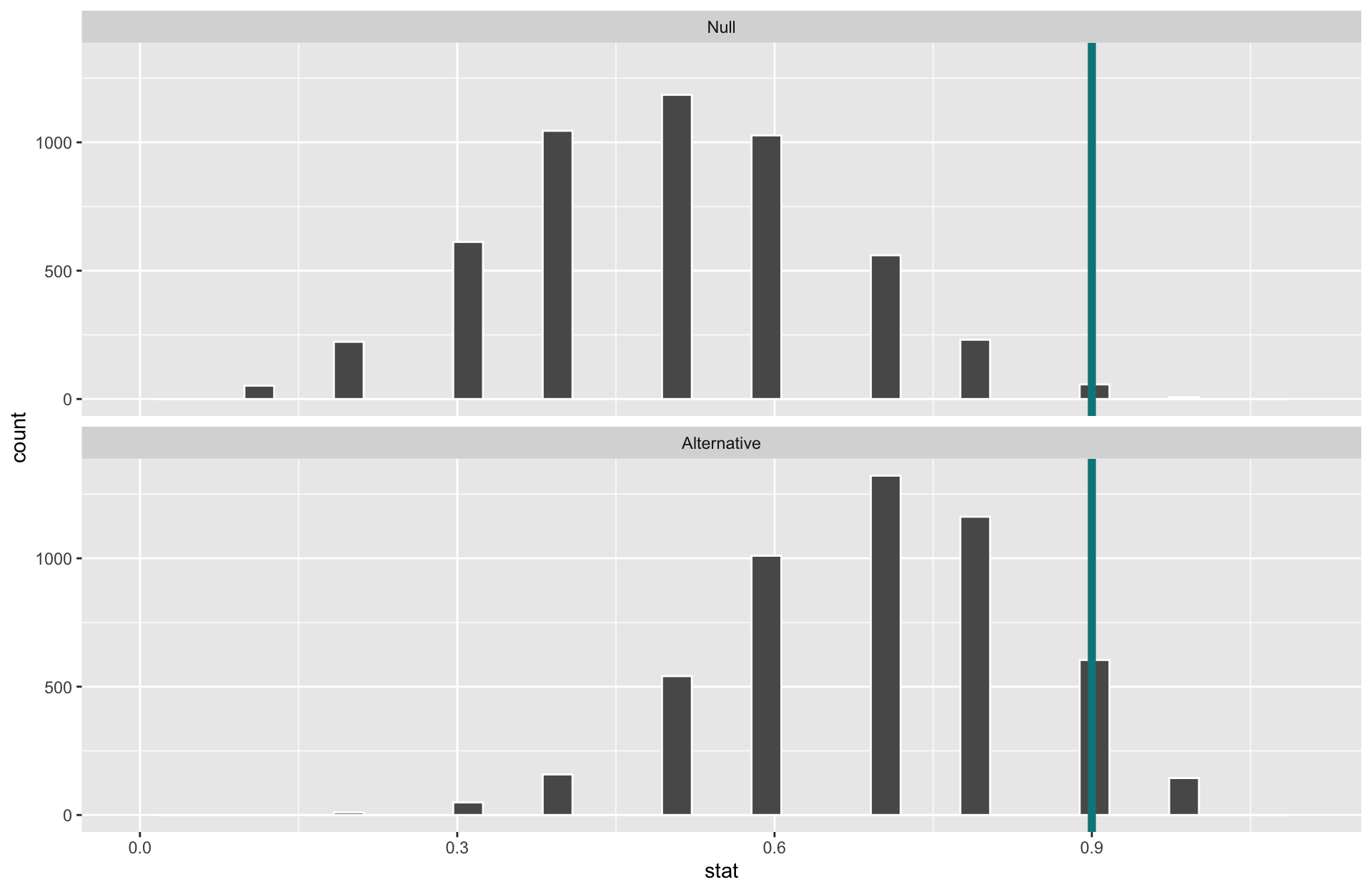
When \(\alpha=0.05\), they need 9 or more correct for a small enough p-value to reject \(H_o\).
When \(\alpha=0.05\), the power of this test is 0.15.
- Why is the power so low? Our power is very much not “unlimited” :(
- What aspects of the test could we change to increase the power of the test?
Example
Suppose we want to test whether someone can detect AI-generated text from real text. We show a participant 10 50 short passages that are each either written by a human or an AI agent, and ask them to identify which are written by AI. Suppose the participant’s true (long-run) detection rate is 70%.
- What will happen to the power of the test if we increase the sample size?
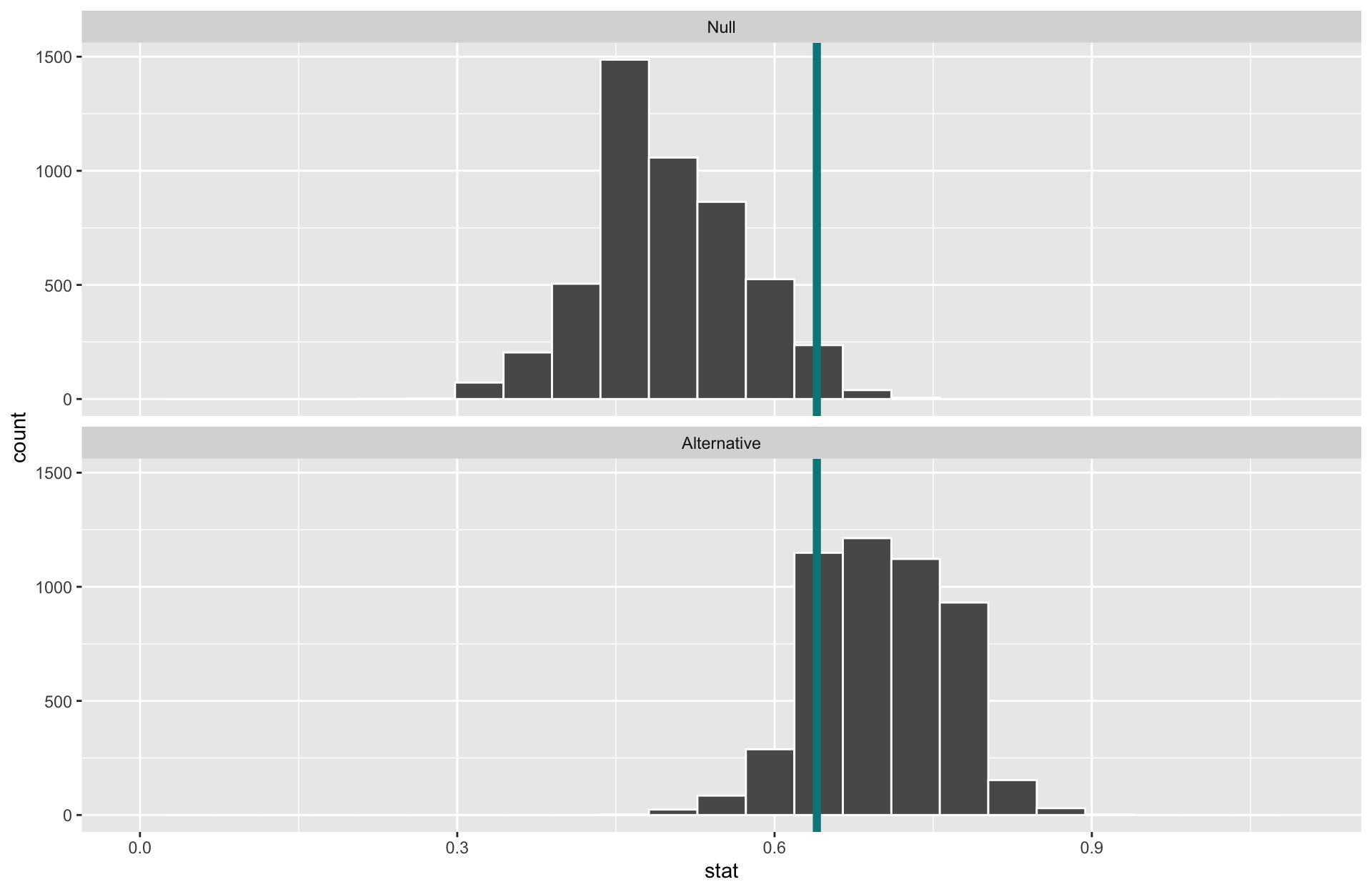
Increasing the sample size narrows the sampling distributions and increases the power.
When \(\alpha\) is set to \(0.05\) and the sample size is now 50, the power of this test is 0.87.
Example
Suppose we want to test whether someone can detect AI-generated text from real text. We show a participant 10 50 short passages that are each either written by a human or an AI agent, and ask them to identify which are written by AI. Suppose the participant’s true (long-run) detection rate is 70%.
- What will happen to the power of the test if we increase \(\alpha\) to 0.1?
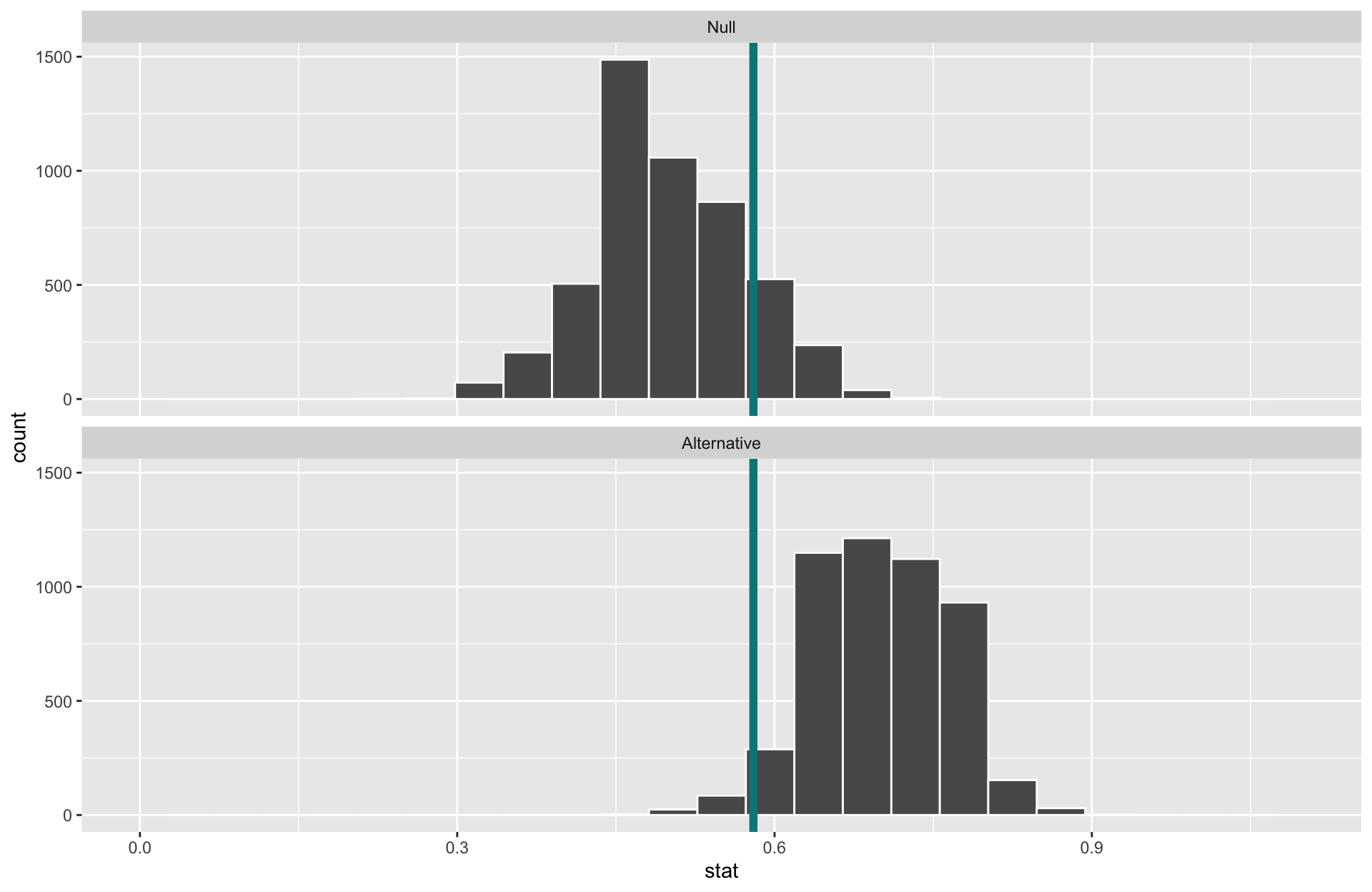
- Increasing \(\alpha\) increases the power.
- Decreases \(\beta\).
- (But remember, also increasing our chances of false alarms)
- When \(\alpha\) is set to \(0.1\) and the sample size is 50, the power of this test is 0.98!
Example
Suppose we want to test whether someone can detect AI-generated text from real text. We show a participant 10 50 short passages that are each either written by a human or an AI agent, and ask them to identify which are written by AI. Suppose the participant’s true (long-run) detection rate is 70% 80%.
- What will happen to the power of the test if the participant is even better at detecting AI?
Effect size: Difference between true value of the parameter and null value.
- Often standardized.
Increasing the effect size increases the power.
When \(\alpha\) is set back to \(0.05\), the sample size is 50, and the true probability of detecting AI is 0.8, the power of this test is 0.998.
Computing Power
- Generate a null distribution:
Computing Power
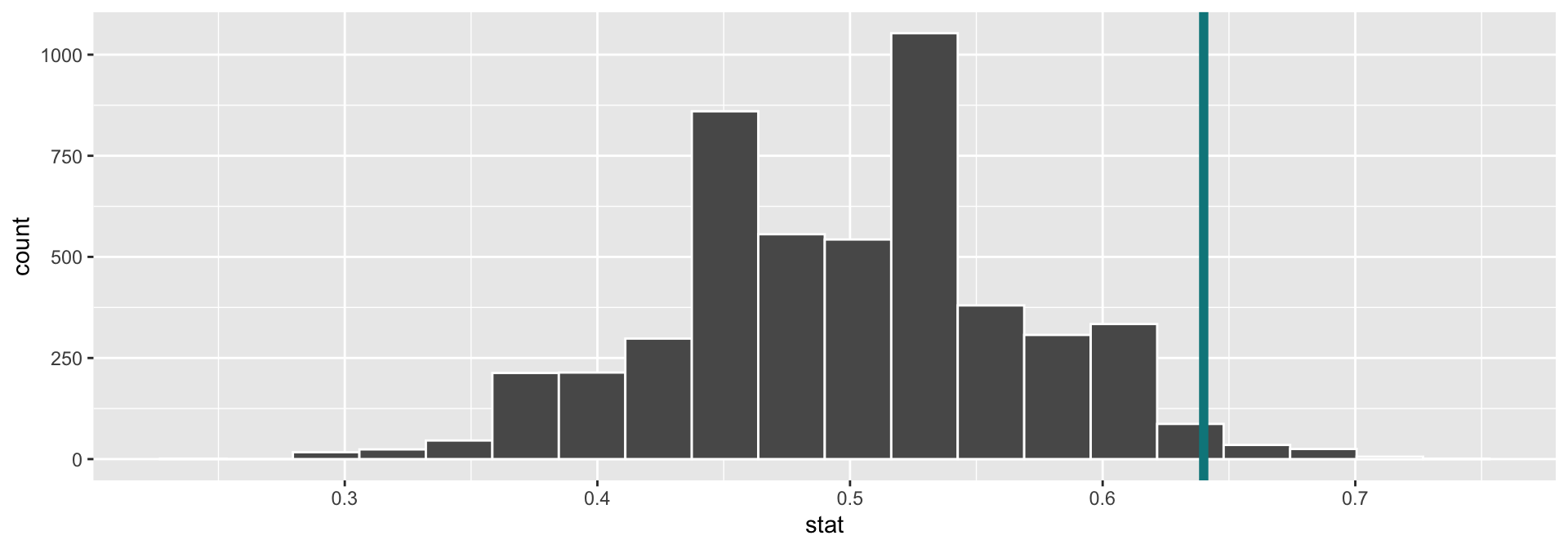
- Determine the “critical value(s)” where \(\alpha = 0.05\) (careful with discrete distributions).
Computing Power
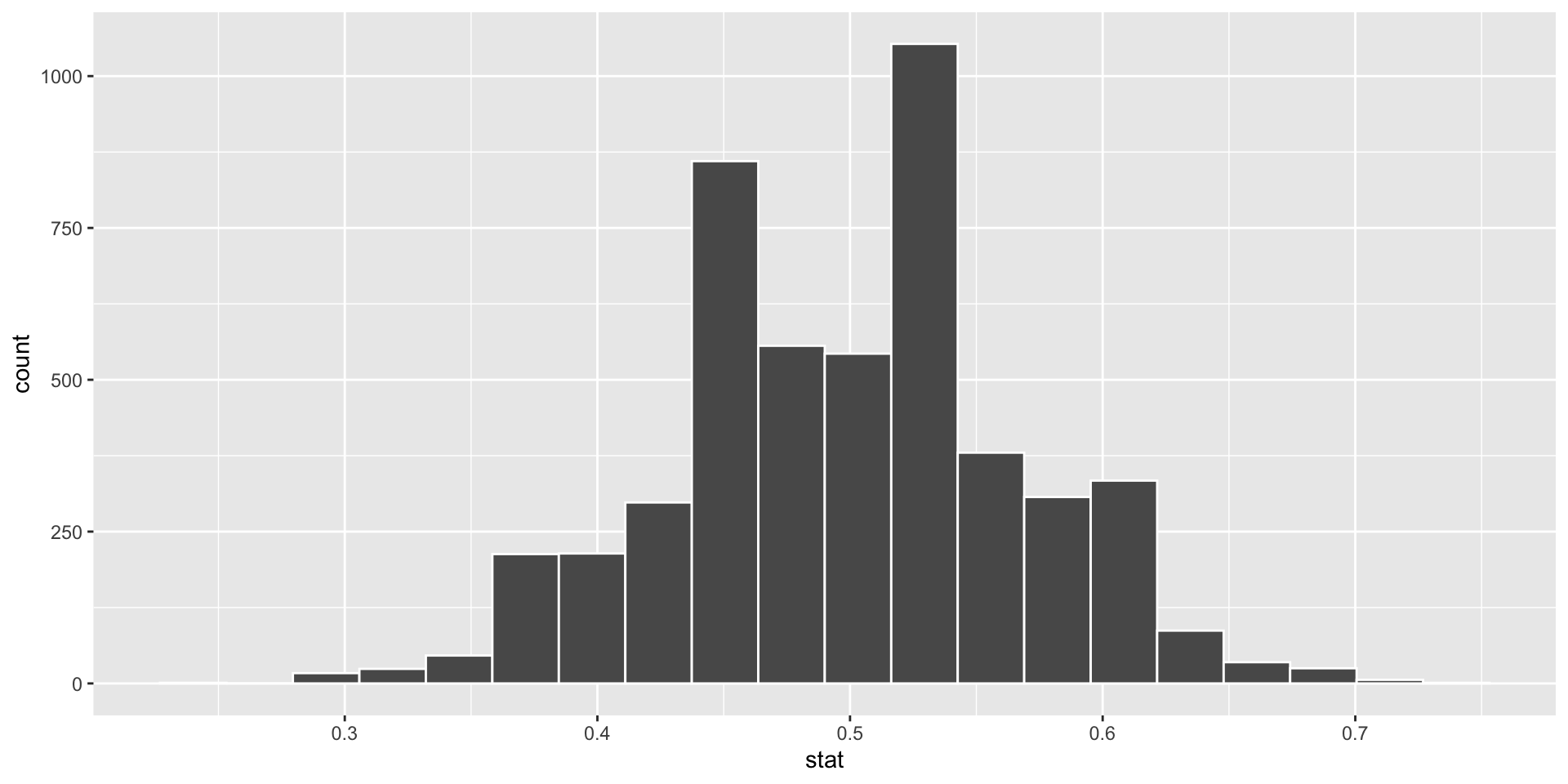
- Construct the alternative distribution. This usually requires a leap of faith - we need to assume a parameter under the alternative hypothesis!
- Draw on any existing evidence (ex. a pilot study) to justify your assumption
alt_stats <- data.frame(correct = rep(c(0, 1),
times = c(3, 7))) %>%
rep_sample_n(size = 50, replace = TRUE,
reps = 5000) %>%
group_by(replicate) %>%
summarize(stat = mean(correct))
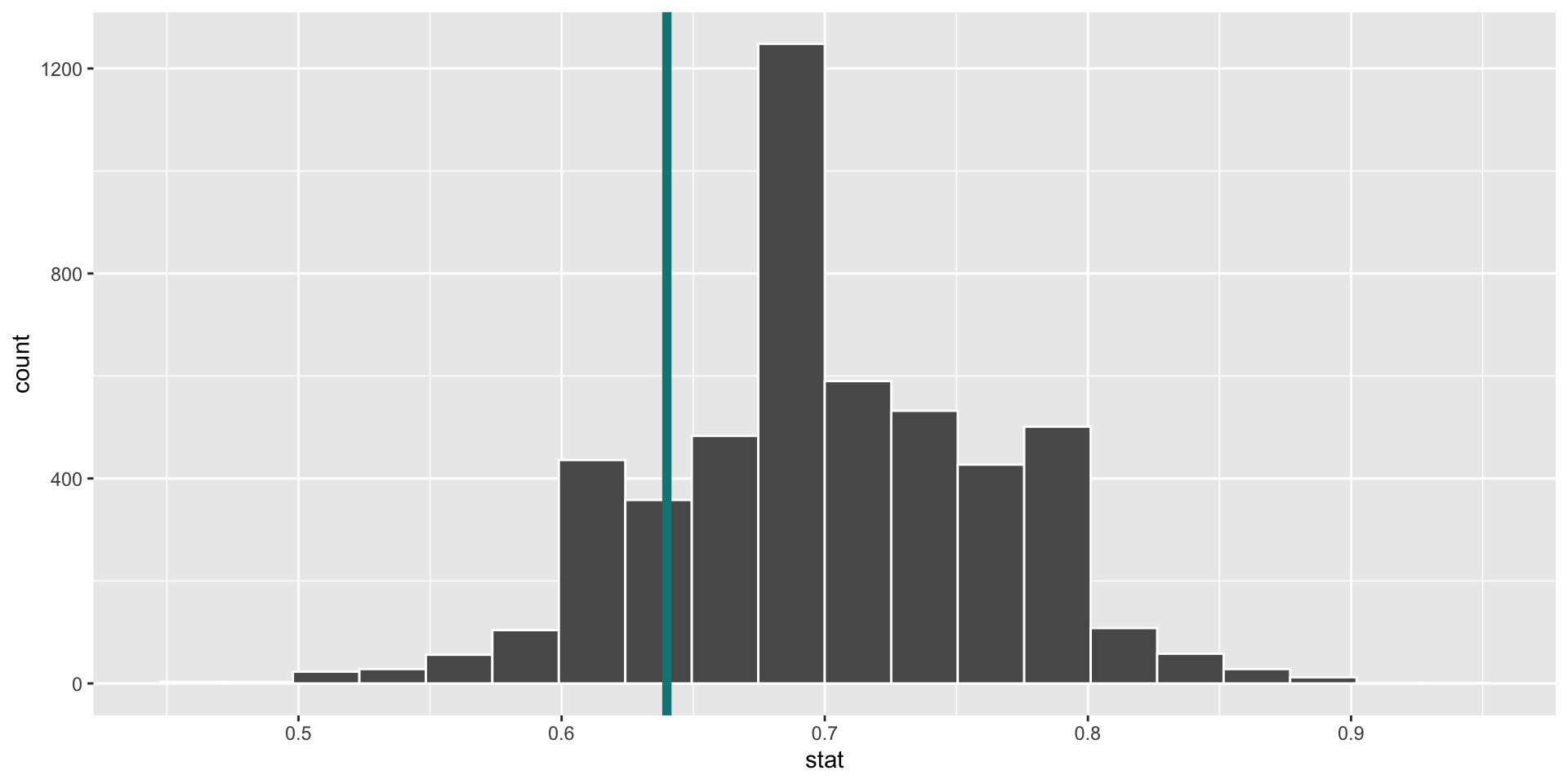
ggplot(data = alt_stats, mapping = aes(x = stat)) +
geom_histogram(bins = 20, color = "white") +
geom_vline(xintercept = 0.64,
size = 2, color = "turquoise4")