
Hypothesis Testing II
Megan Ayers
Math 141 | Spring 2026
Monday, Week 8
Example: Does Extrasensory Perception (ESP) exist?
Psychologists Bem and Honorton conducted extrasensory perception studies:
- A “sender” randomly chooses an object out of 4 possible objects and sends that information to a “receiver”.
- The “receiver” is then given a set of 4 possible objects and they must decide which one most resembles the object sent to them.
Out of 329 reported trials, the “receivers” correctly identified the object 106 times.
Hypothesis Testing Steps: ESP
- Describe “Null” distribution. How might we simulate it?
- The distribution of \(\widehat{p}\) (the proportion of correct guesses) we would see if participants guess at random each time.
Steps to simulate this:
- Sample with replacement from a vector of 0’s and 1’s, where we have a 25% chance of sampling 1 each time
- Compute proportion of 1’s sampled
- Repeat 1 and 2 many times.
set.seed(123)
guesses <- c(0, 0, 0, 1) # Like a 4-sided dice with sides 0, 0, 0, 1
null_stats <- data.frame(correct = guesses) %>%
rep_sample_n(size = 329, replace = TRUE,
reps = 10000) %>%
group_by(replicate) %>%
summarize(p_hat = mean(correct))
ggplot(null_stats, aes(x = p_hat)) + geom_histogram(color = "white")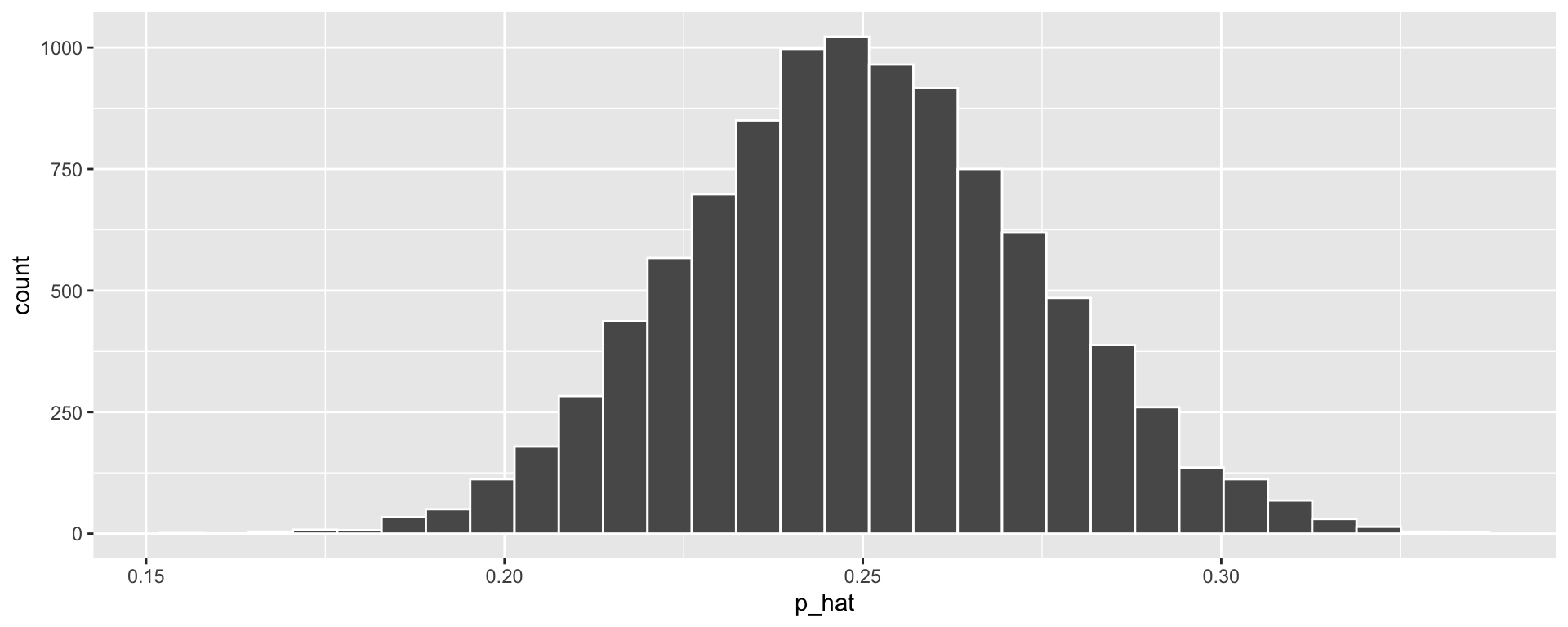
Hypothesis Testing Steps: ESP
- Describe “Null” distribution. How might we simulate it?
- The distribution of \(\widehat{p}\) (the proportion of correct guesses) we would see if participants guess at random each time.
Steps to simulate this:
- Sample with replacement from a vector of 0’s and 1’s, where we have a 25% chance of sampling 1 each time
- Compute proportion of 1’s sampled
- Repeat 1 and 2 many times.
set.seed(123)
guesses <- c(0, 0, 0, 1) # Like a 4-sided dice with sides 0, 0, 0, 1
null_stats <- data.frame(correct = guesses) %>%
rep_sample_n(size = 329, replace = TRUE,
reps = 10000) %>%
group_by(replicate) %>%
summarize(p_hat = mean(correct))
ggplot(null_stats, aes(x = p_hat)) + geom_histogram(color = "white")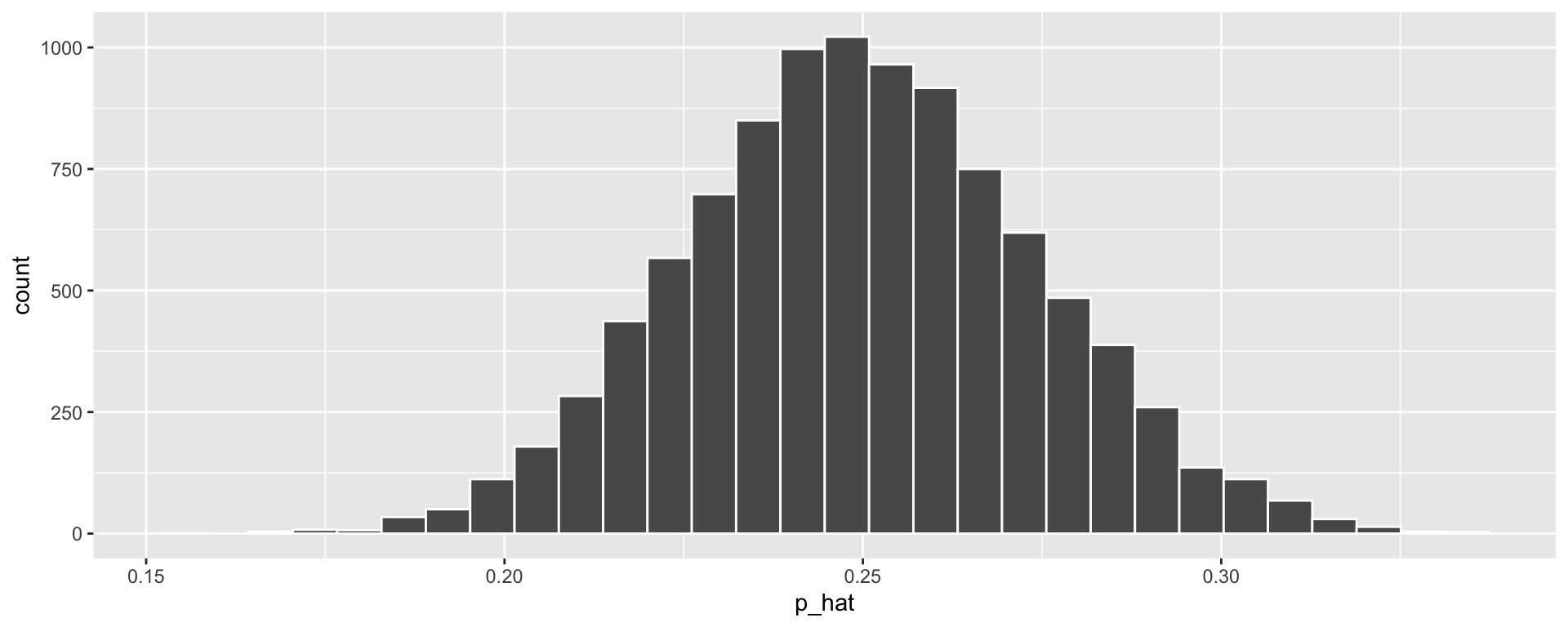
Hypothesis Testing Steps: ESP
- Describe “Null” distribution. How might we simulate it?
- The distribution of \(\widehat{p}\) (the proportion of correct guesses) we would see if participants guess at random each time.
Steps to simulate this:
- Sample with replacement from a vector of 0’s and 1’s, where we have a 25% chance of sampling 1 each time
- Compute proportion of 1’s sampled
- Repeat 1 and 2 many times.
set.seed(123)
guesses <- c(0, 0, 0, 1) # Like a 4-sided dice with sides 0, 0, 0, 1
null_stats <- data.frame(correct = guesses) %>%
rep_sample_n(size = 329, replace = TRUE,
reps = 10000) %>%
group_by(replicate) %>%
summarize(p_hat = mean(correct))
ggplot(null_stats, aes(x = p_hat)) + geom_histogram(color = "white")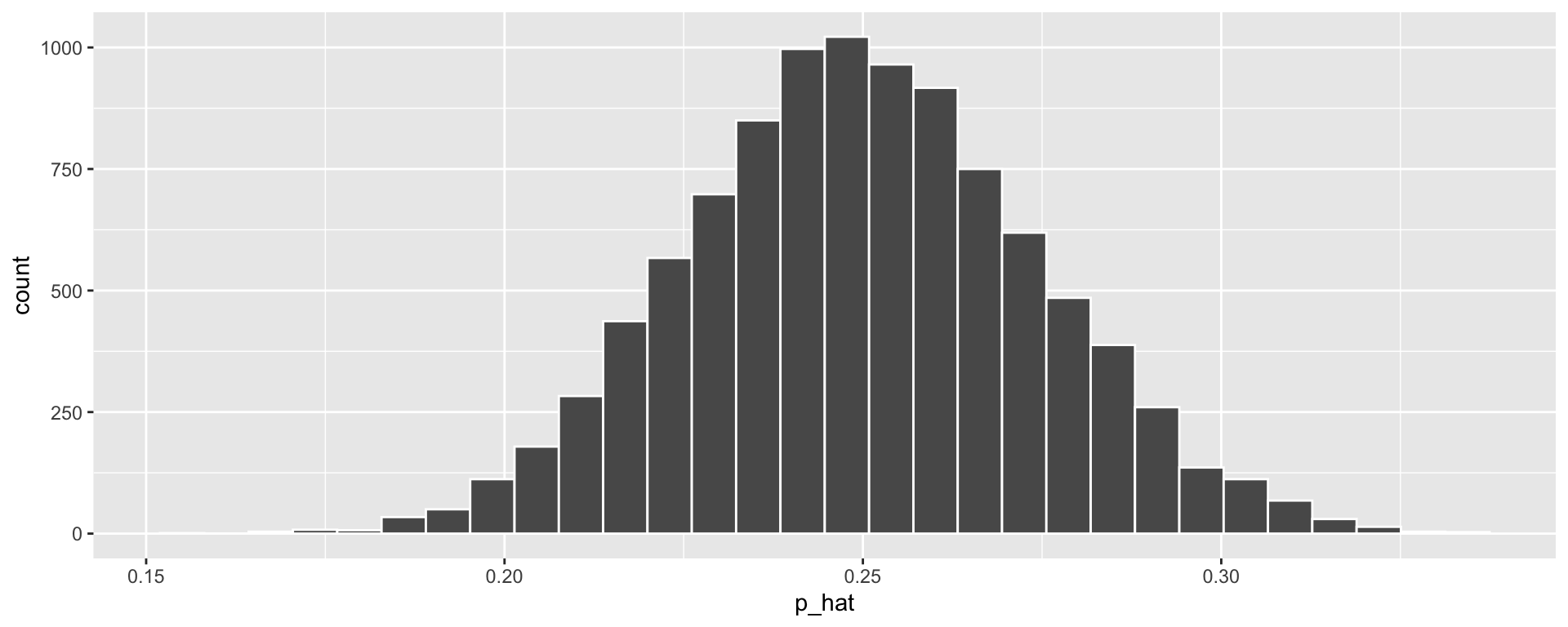
Hypothesis Testing Steps: ESP
- Describe “Null” distribution. How might we simulate it?
- The distribution of \(\widehat{p}\) (the proportion of correct guesses) we would see if participants guess at random each time.
Steps to simulate this:
- Sample with replacement from a vector of 0’s and 1’s, where we have a 25% chance of sampling 1 each time
- Compute proportion of 1’s sampled
- Repeat 1 and 2 many times.
set.seed(123)
guesses <- c(0, 0, 0, 1) # Like a 4-sided dice with sides 0, 0, 0, 1
null_stats <- data.frame(correct = guesses) %>%
rep_sample_n(size = 329, replace = TRUE,
reps = 10000) %>%
group_by(replicate) %>%
summarize(p_hat = mean(correct))
ggplot(null_stats, aes(x = p_hat)) + geom_histogram(color = "white")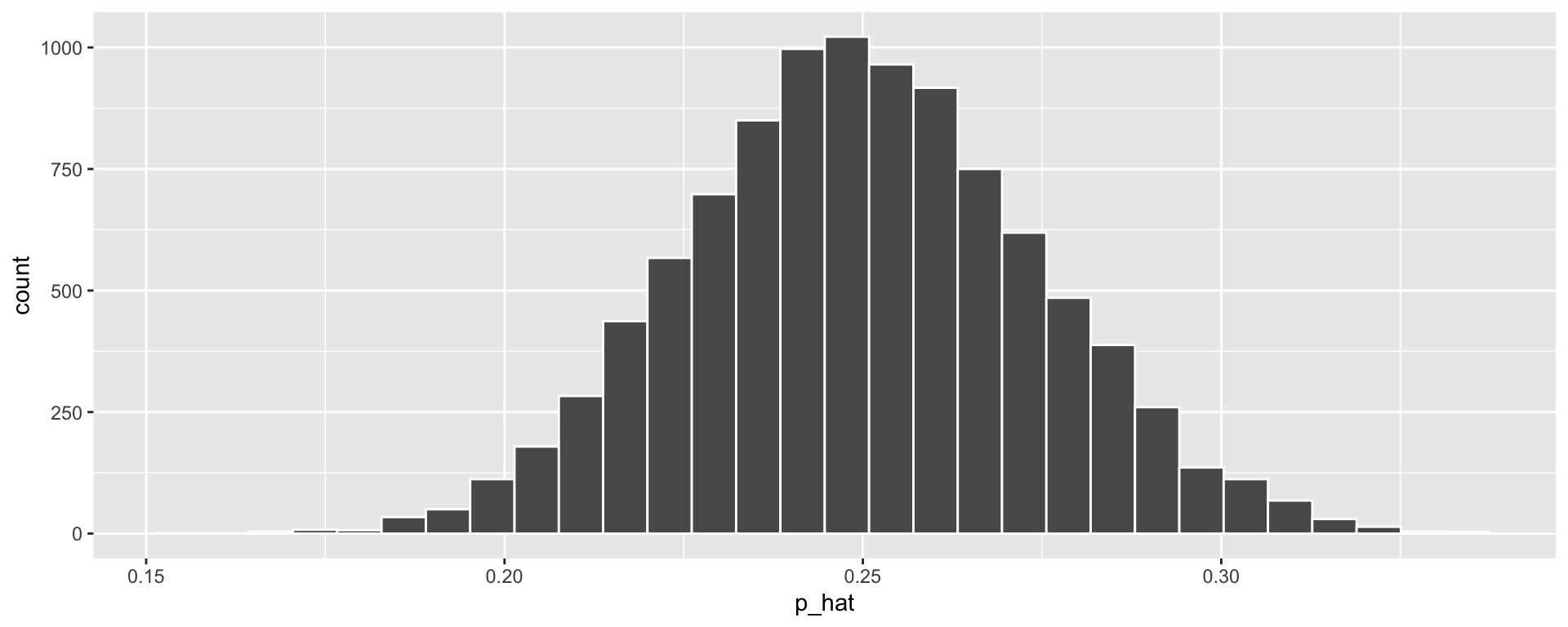
Hypothesis Testing Steps: ESP
- What is our relevant “Test Statistic”?
- \(\widehat{p}\) = 106 / 329 = 0.32
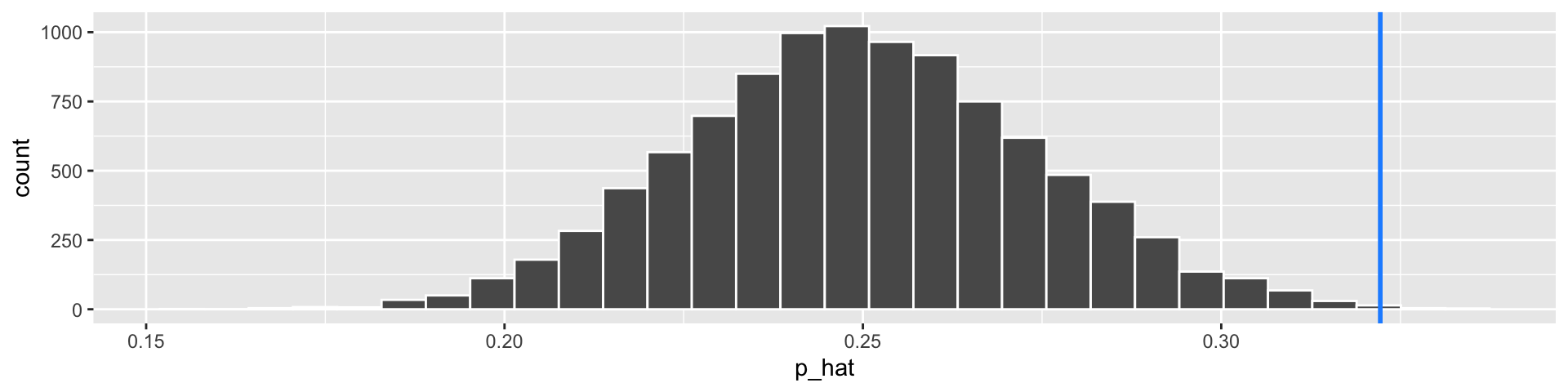
- How can we calculate the “P-value”?
- Can use probability theory to find \(P(\text{Correct guesses} \geq 106) = \ldots ?\)
- Or our simulated null distribution
- How would we use the P-value to make a conclusion on the research question?
- If the p-value is “small enough”, we reject the null hypothesis of random guessing.
Hypothesis Testing: ESP
We got a pretty small p-value (\(0.0013\)). Hooray! It is reasonable to reject the null hypothesis.
But really, do we believe that ESP is real?
- Next lecture, we’ll talk more about hypothesis testing errors.
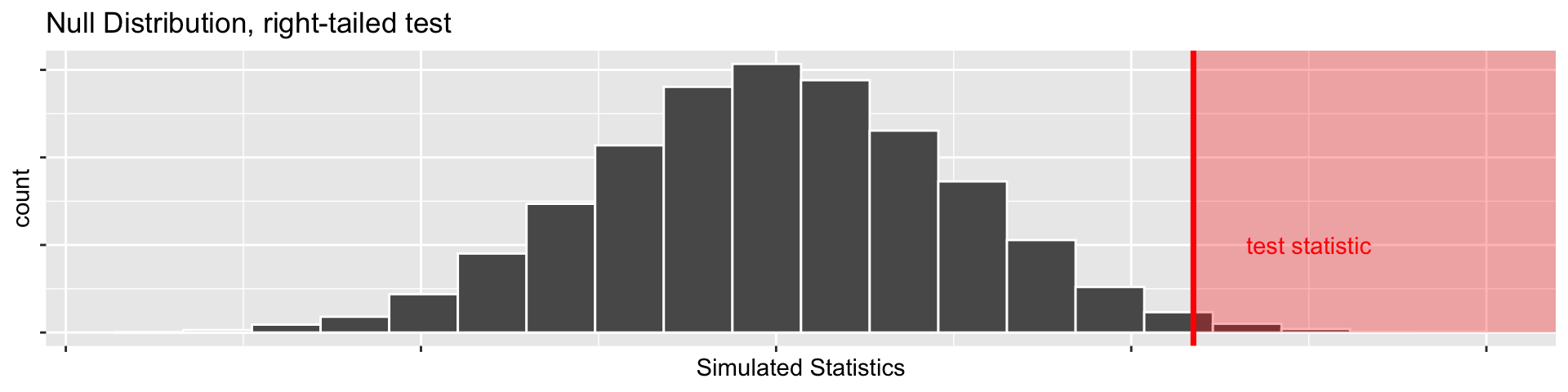
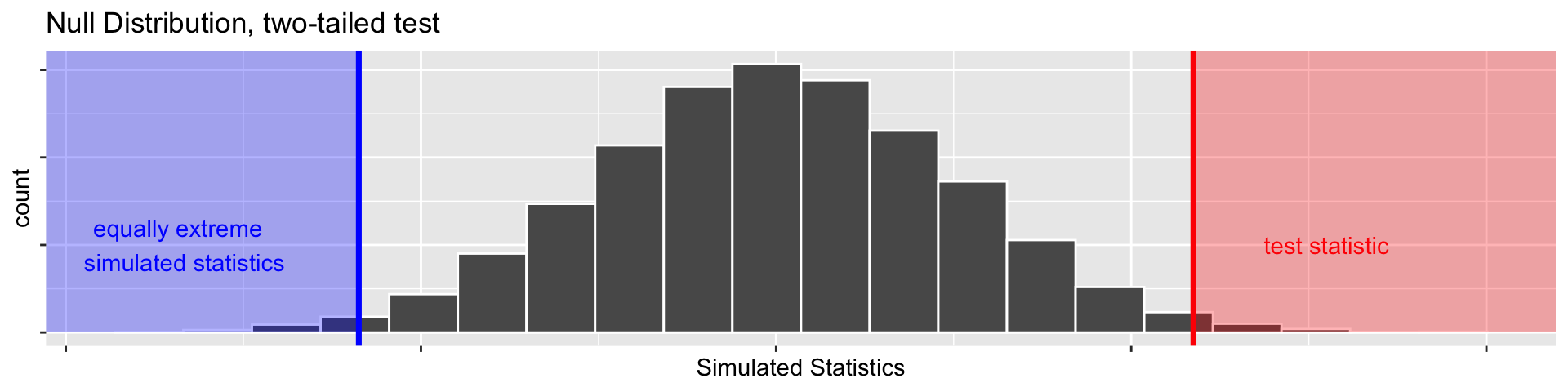
1 vs 2 sided tests: what does “more extreme” mean?
- Suppose our test statistic from 20 coin flips is \(\widehat{p}= 0.85\).
- If we have \(H_a: p > 0.5\) (right-tailed test)
- We’d want \(\mathrm{P}(\widehat{p} \geq 0.85)\) under the null hypothesis as our P-value
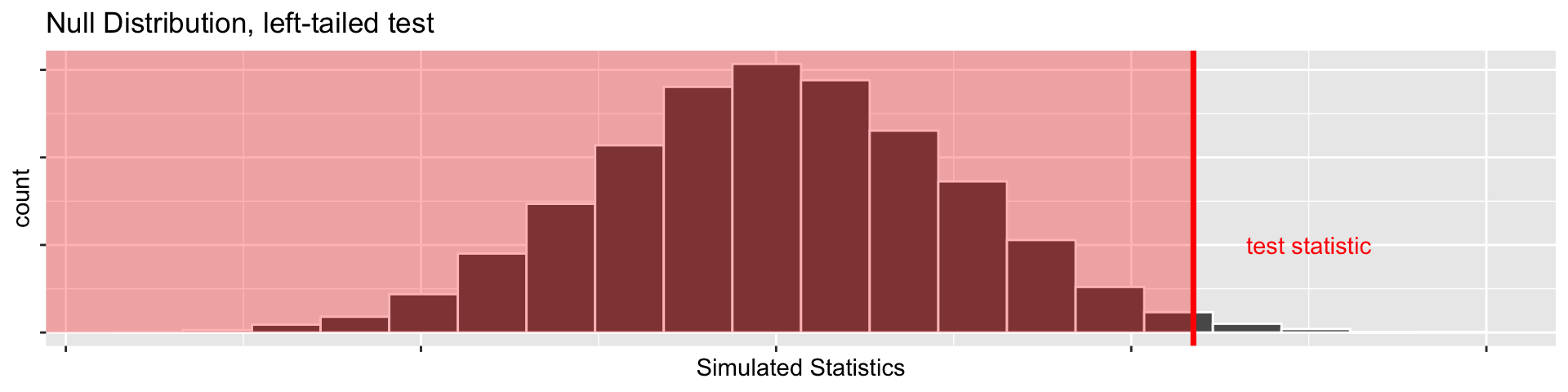
1 vs 2 sided tests: what does “more extreme” mean?
- Suppose our test statistic from 20 coin flips is \(\widehat{p}= 0.85\).
- Suppose we have \(H_a: p \neq 0.5\)
- \(\widehat{p}= 0.85\) is 0.35 more than \(p = 0.5\), so we want to include \(\mathrm{P}(\widehat{p} \geq 0.85)\)
- \(\widehat{p}= 0.15\) is 0.35 less than \(p = 0.5\), so we’d also want \(\mathrm{P}(\widehat{p} \leq 0.15)\) (this would be more extreme in the other direction)
- So our P-value would be the sum of those two things (both tails)!
Null distributions: how to generate them for these other examples?
- Rat Pain and grimacing :(
- \(H_0\): The correlation between grimacing and the level of pain is 0
- Under the null, grimacing and level of pain are totally unrelated
- To approximate the null distribution, we could:
- Randomly shuffle the
grimacecolumn of our data - Calculate the correlation between
grimaceandpainin the shuffled data - Repeat 1-2 many times.
- Randomly shuffle the
set.seed(111)
df <- data.frame(pain = runif(100, 0, 10),
grimace = rnorm(100, 10, 2))
null_stats <- df %>% select(grimace) %>%
rep_sample_n(size = 100, replace = FALSE,
reps = 5000) %>%
add_column(pain = rep(df$pain, times = 5000)) %>%
group_by(replicate) %>%
summarize(stat = cor(grimace, pain))
ggplot(null_stats, aes(x = stat)) +
geom_histogram(color = "white", fill = "gray60") +
geom_vline(aes(xintercept = 0), lty = 2,
col = "black", lwd = 1) +
theme_classic()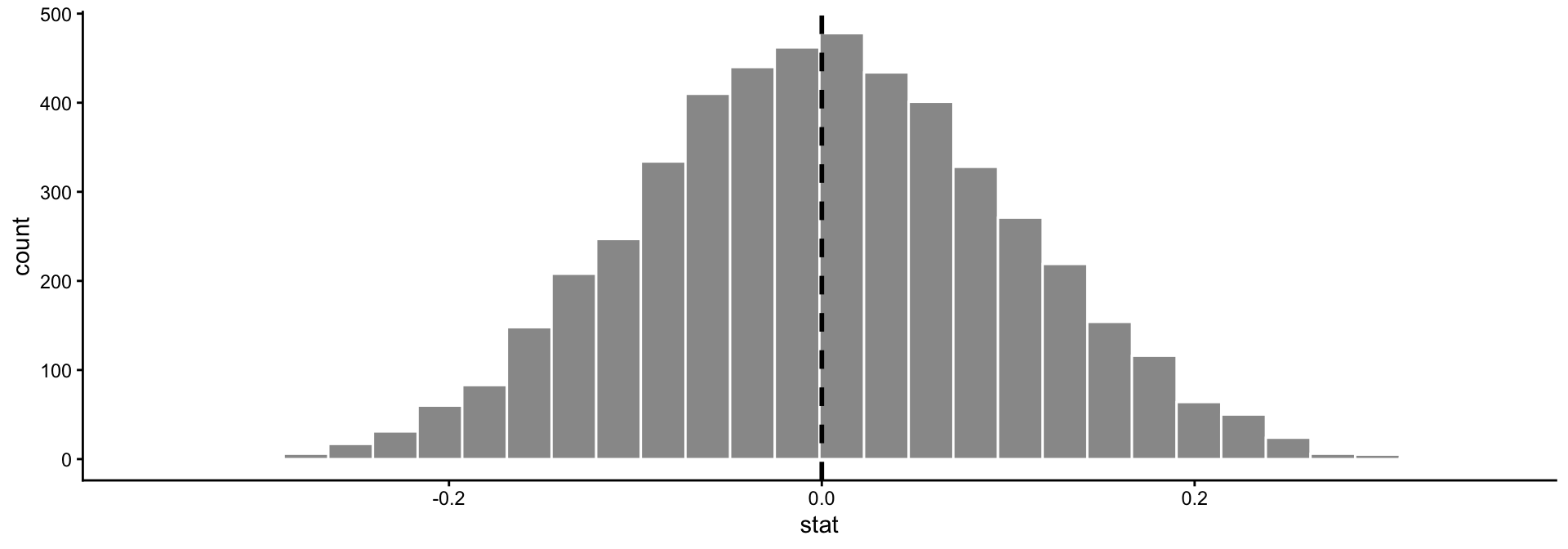
Null distributions: how to generate them for these other examples?
- Discipline for Smilers vs Non-Smilers
- \(H_0\): We expect the difference in average leniency scores between the smiling and non-smiling groups to be zero - no relationship between the leniency score and the treatment group.
- To approximate the null distribution, we could:
- Randomly shuffle the
treatmentcolumn of our data - Calculate the difference in means between the leniency scores in each group
- Repeat 1-2 many times.
- Randomly shuffle the
set.seed(111)
df <- data.frame(treatment = rep(c("smile", "neutral"), times = 30),
score = round(runif(60, 0, 10)))
null_stats <- df %>% select(treatment) %>%
rep_sample_n(size = 60, replace = FALSE, reps = 5000) %>%
add_column(score = rep(df$score, times = 5000)) %>%
group_by(replicate, treatment) %>%
summarize(ybar = mean(score)) %>%
pivot_wider(names_from = treatment, values_from = ybar) %>%
mutate(stat = smile - neutral)
ggplot(null_stats, aes(x = stat)) +
geom_histogram(color = "white", fill = "gray60") +
geom_vline(aes(xintercept = 0), lty = 2, col = "black", lwd = 1) +
theme_classic()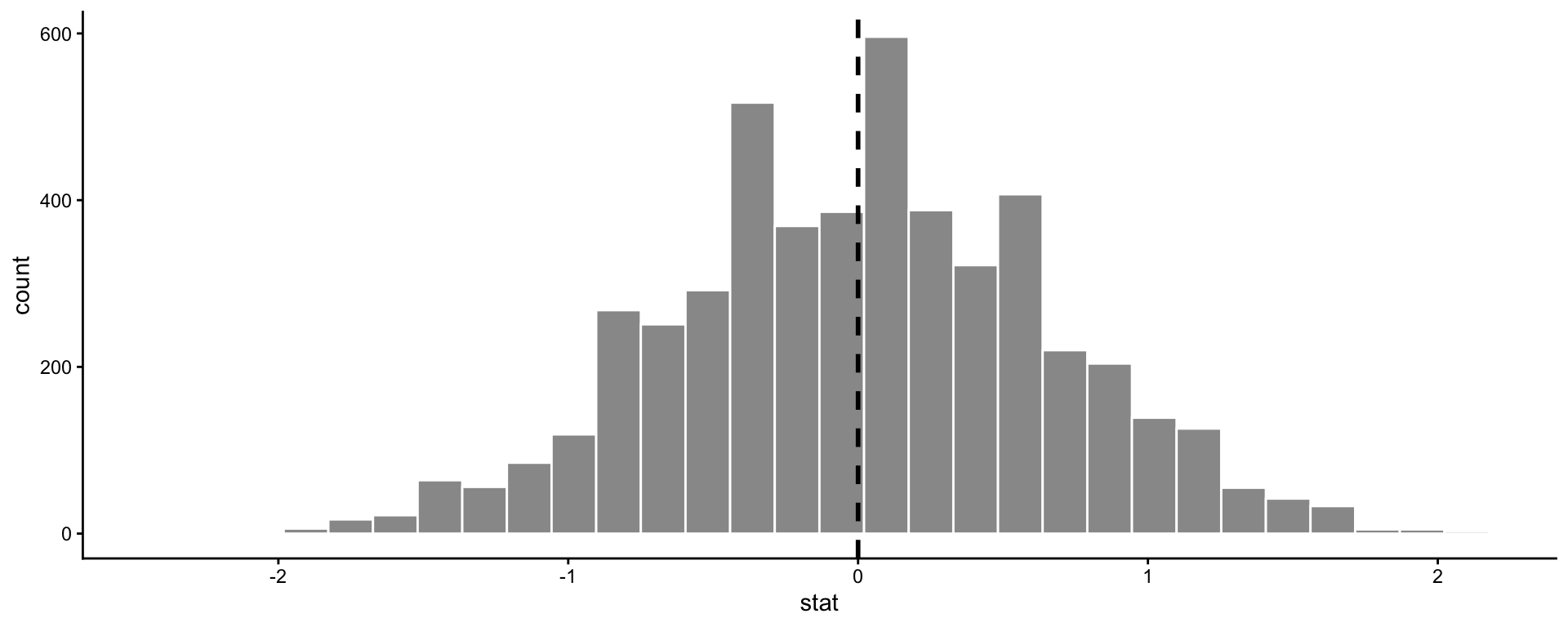
Next time
- Decisions in hypothesis testing
- Types of hypothesis testing errors
- Power
