Linear Models V
Megan Ayers
Math 141 | Spring 2026
Wednesday, Week 5
More time with the palmerpenguins!

This time: Regression with multiple quantitative predictors
\[ y = \beta_0 + \beta_1x_{\textrm{Bill Depth}} + \beta_2 x_{\textrm{Body Mass}} + \epsilon \]
Model Building Guidance
Should we always include an interaction term? How many variables should I include?
Guiding Principle: Occam’s Razor for Modeling
“All other things being equal, simpler models are to be preferred over complex ones.” – ModernDive
Guiding Principle: Consider your modeling goals.
- The equal slopes model allows us to control for the intensity of the light and then see the impact of being in the early or late timing groups on the number of flowers.
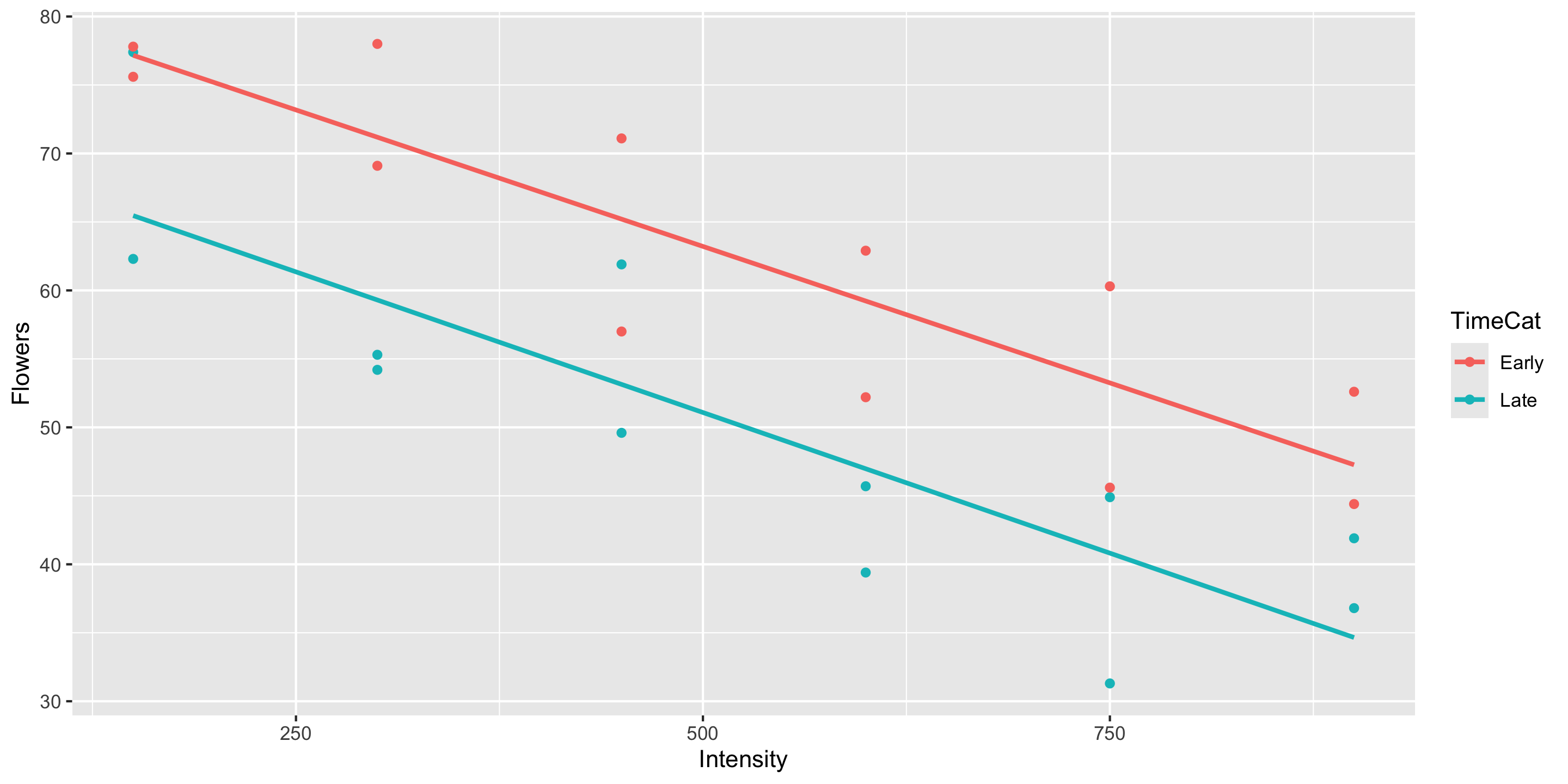
- Later in the course will learn statistical procedures for determining whether or not a particular term should be included in the model.
Example: Movie Ratings
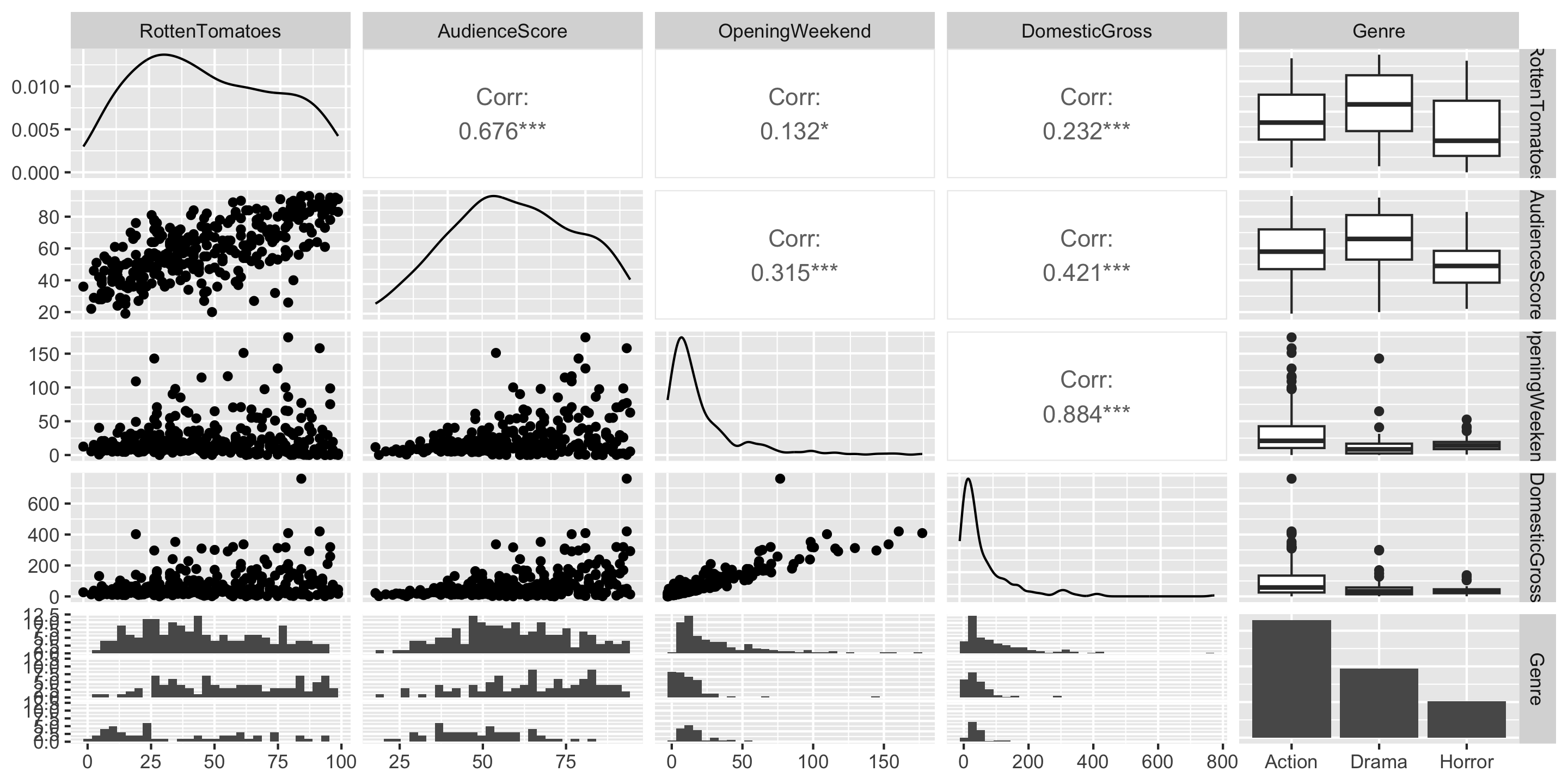
Multicollinearity: when explanatory variables are highly correlated with one another. Multicollinearity often results in coefficients that are distorted in erroneous ways!
Q: Do any of these variables seem to be measuring the same thing?
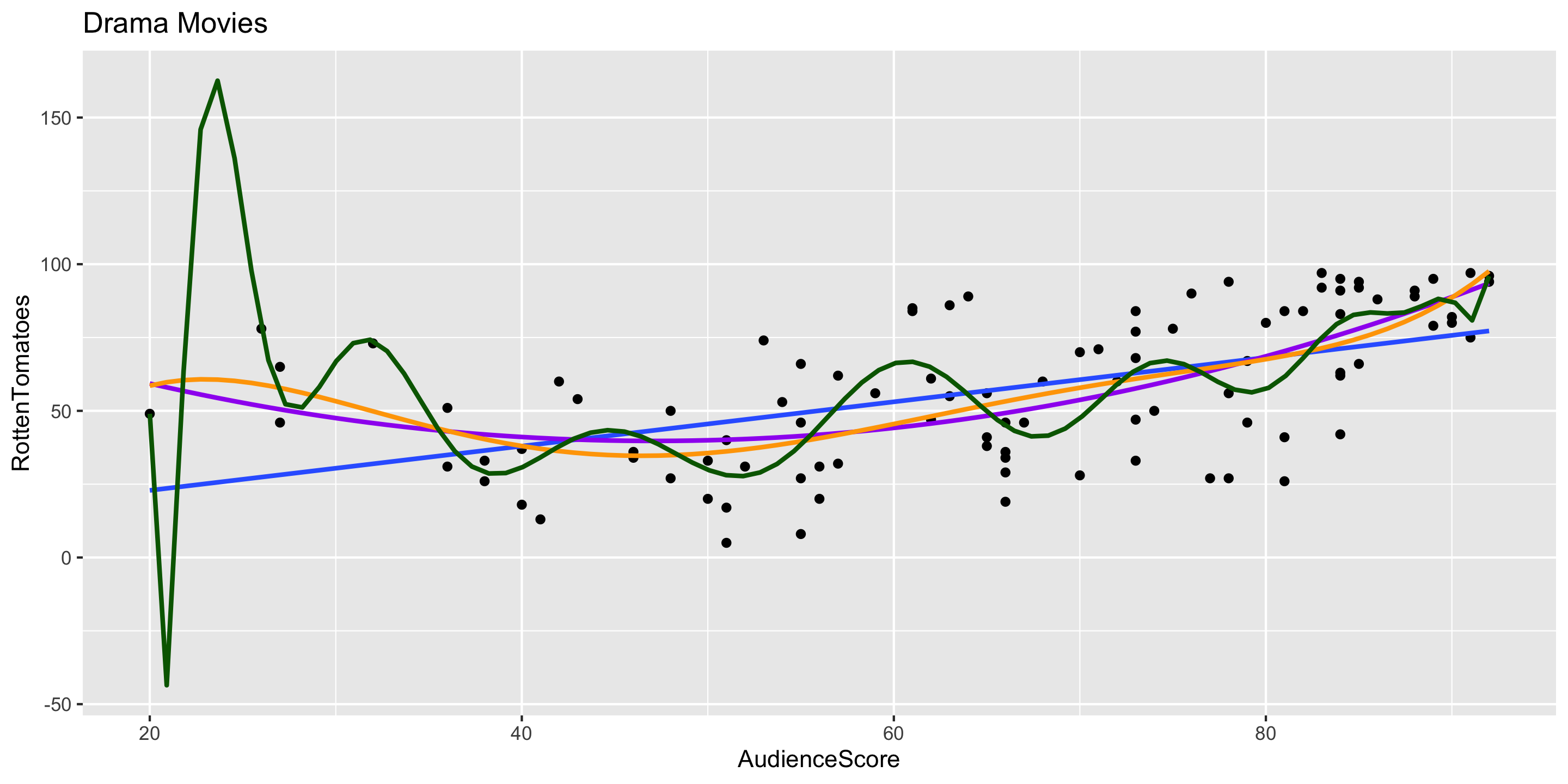
Transformations: Model Building Guidance
What degree of polynomial should I include in my model?
Guiding Principle: Capture the general trend, not the noise.
\[ \begin{align} y &= f(x) + \epsilon \\ y &= \mbox{TREND} + \mbox{NOISE} \end{align} \]
Case Study: Home Prices in King County, WA
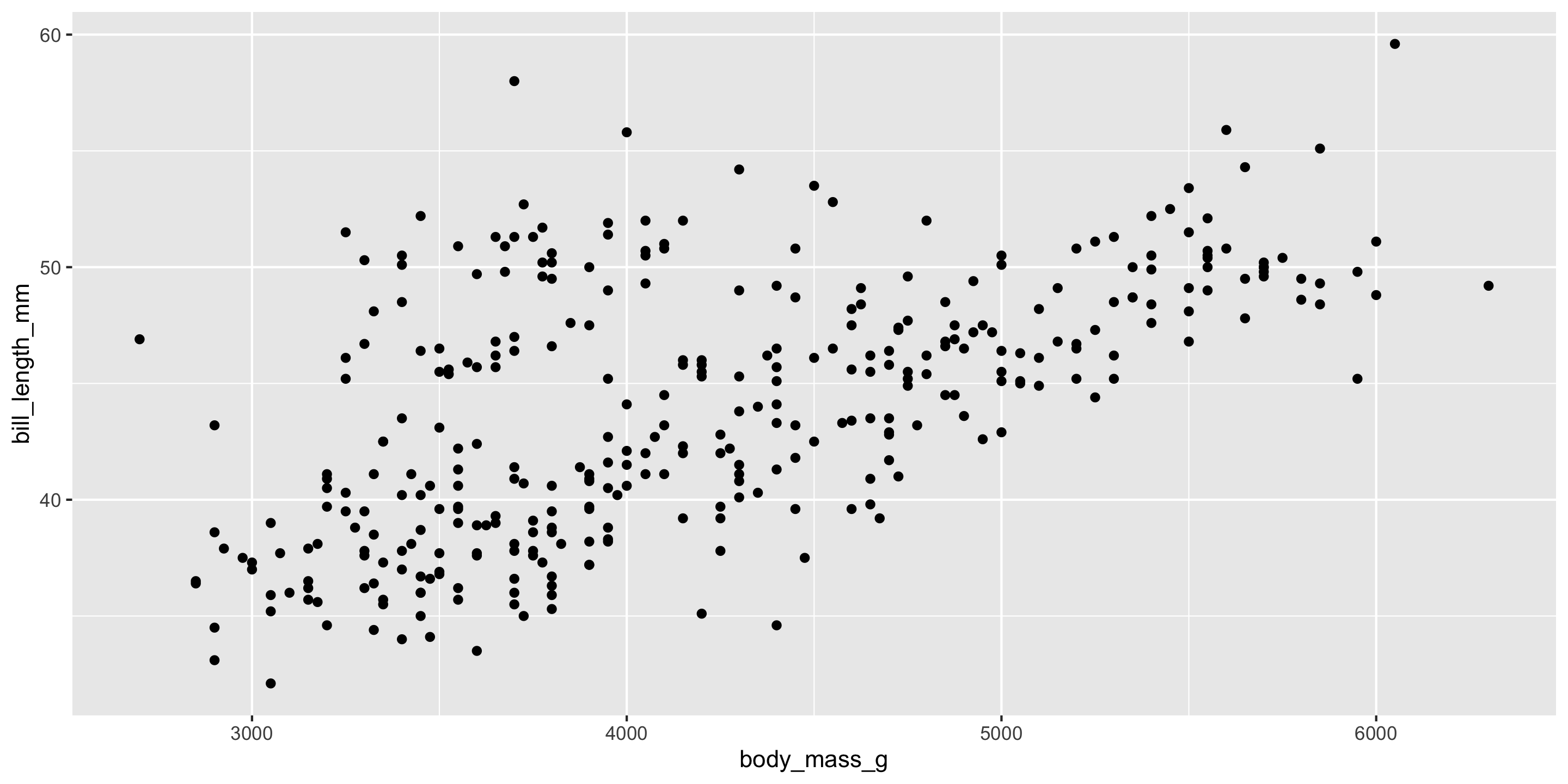
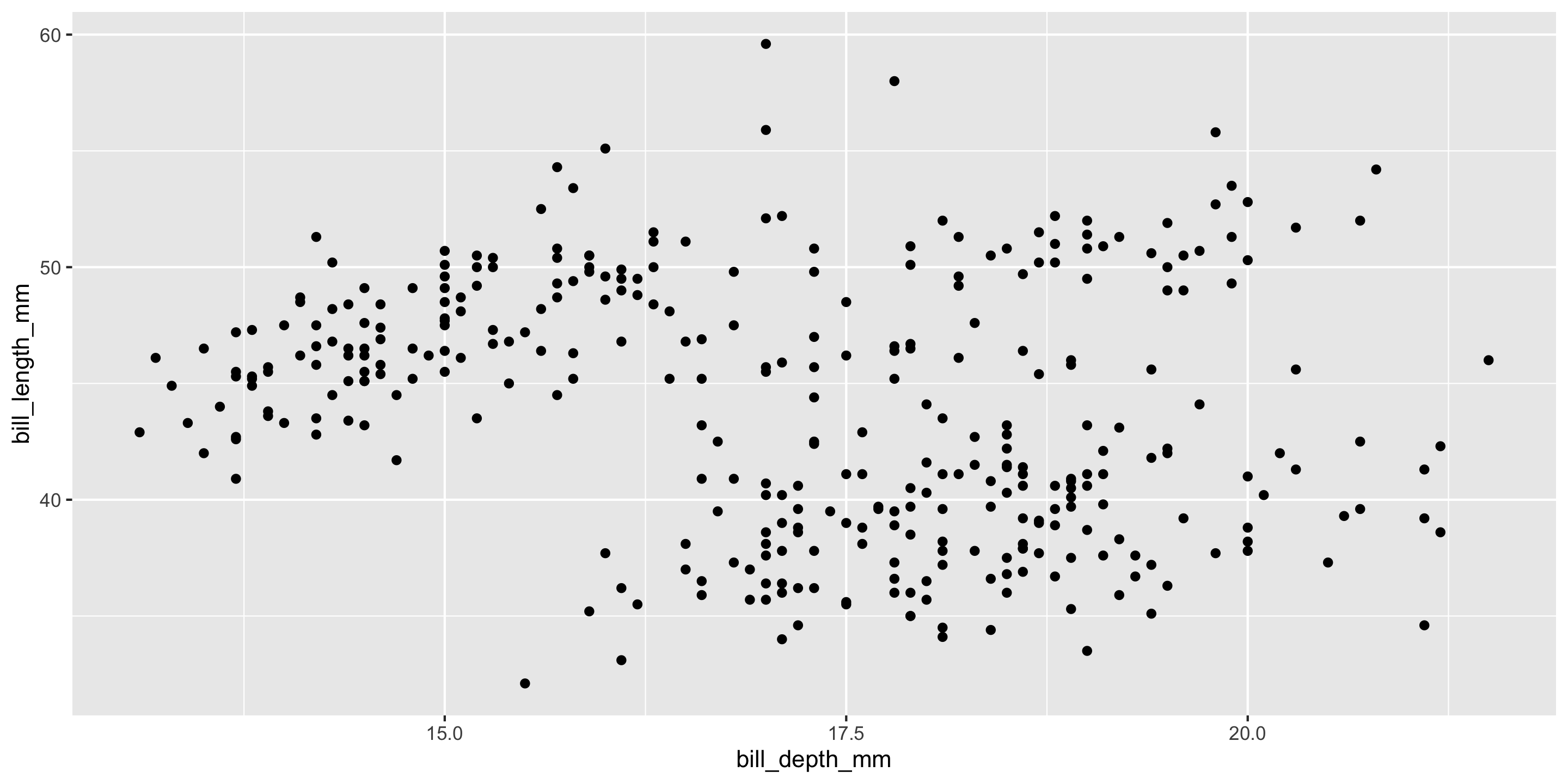
We’ll consider : Sale price (response); and square footage, above-ground square footage, and number of bedrooms (potential explanatory variables). Check out the exploratory plots below:
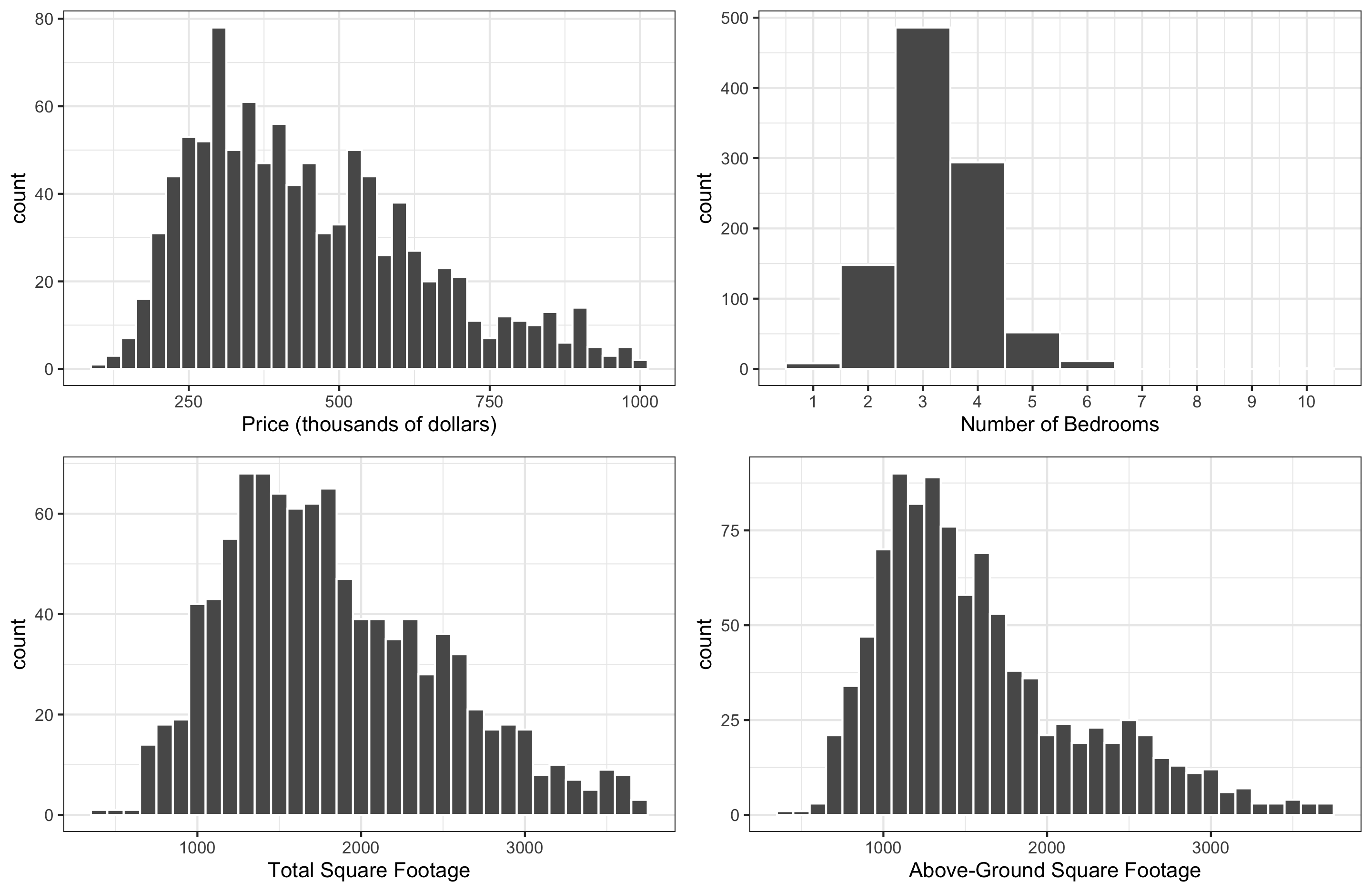
Q: How would you describe the distribution of
price?Q: What do you expect the relationship between
priceandbedroomsto be like?
Exploration, Multicollinearity
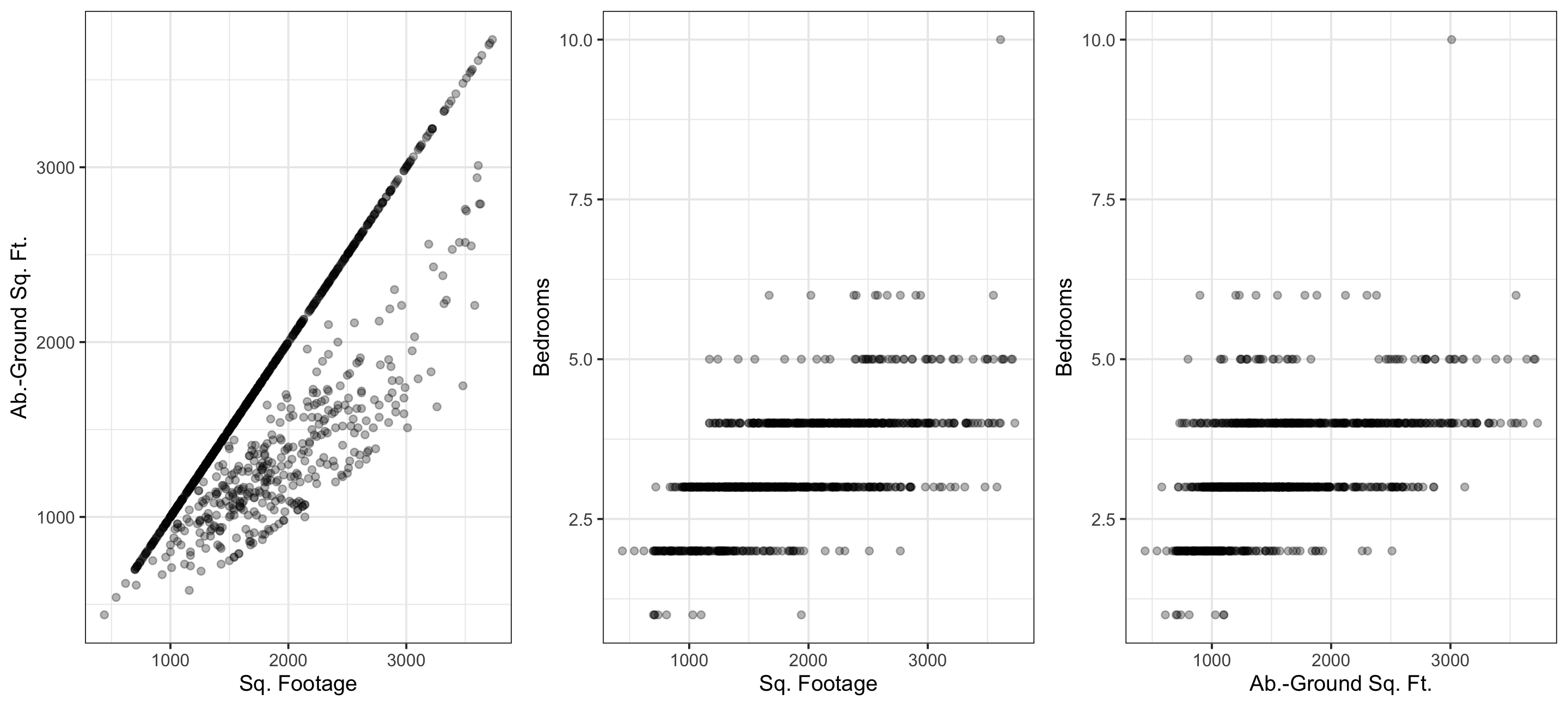
Multicollinearity: when explanatory variables are highly correlated with one another. Multicollinearity often results in coefficients that are distorted in erroneous ways! We want to avoid this (some correlation is okay!)
Q: Which pair of explanatory variables suffers most from multicollinearity?
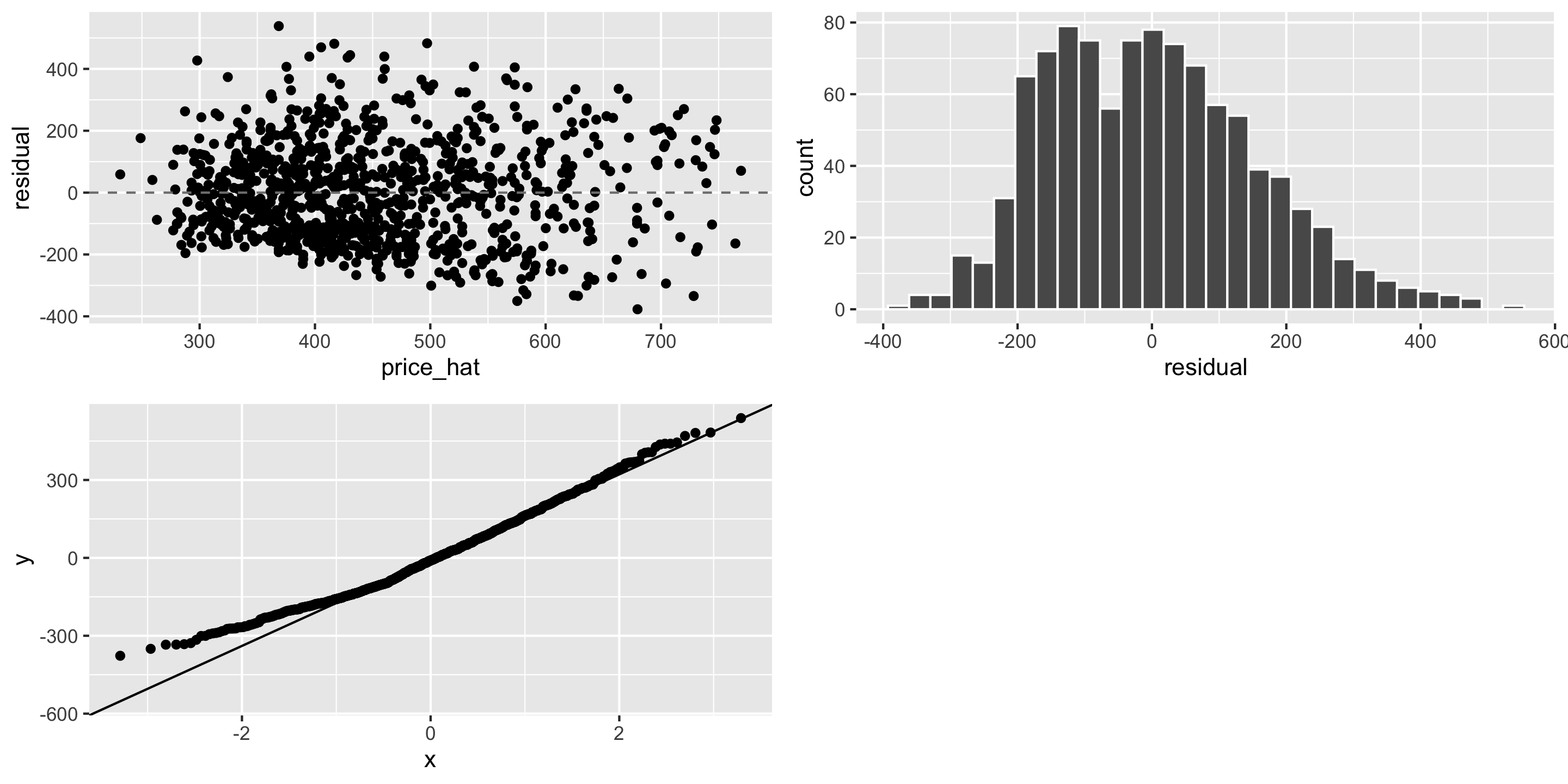
LINE Assumptions