'data.frame': 9999 obs. of 19 variables:
$ RouteID : int 4074085 3719219 3789757 3576798 3459987 3947695 3549550 4411957 4098004 4096862 ...
$ PaymentPlan : chr "Subscriber" "Casual" "Casual" "Subscriber" ...
$ StartHub : chr "SE Elliott at Division" "SW Yamhill at Director Park" "NE Holladay at MLK" "NW Couch at 2nd" ...
$ StartLatitude : num 45.5 45.5 45.5 45.5 45.5 ...
$ StartLongitude : num -123 -123 -123 -123 -123 ...
$ StartDate : chr "8/17/2017" "7/22/2017" "7/27/2017" "7/12/2017" ...
$ StartTime : chr "10:44:00" "14:49:00" "14:13:00" "13:23:00" ...
$ EndHub : chr "Blues Fest - SW Waterfront at Clay - Disabled" "SW 2nd at Pine" "NE Alberta at NE 29th/30th - Community Corral" "NW Raleigh at 21st" ...
$ EndLatitude : num 45.5 45.5 45.6 45.5 45.5 ...
$ EndLongitude : num -123 -123 -123 -123 -123 ...
$ EndDate : chr "8/17/2017" "7/22/2017" "7/27/2017" "7/12/2017" ...
$ EndTime : chr "10:56:00" "15:00:00" "14:42:00" "13:38:00" ...
$ TripType : logi NA NA NA NA NA NA ...
$ BikeID : int 6163 6843 6409 7375 6354 6088 6089 5988 6857 6847 ...
$ BikeName : chr "0488 BIKETOWN" "0759 BIKETOWN" "0614 BIKETOWN" "0959 BETRUE MAX - RECON" ...
$ Distance_Miles : num 1.91 0.72 3.42 1.81 4.51 5.54 1.59 1.03 0.7 1.72 ...
$ Duration : num 11.5 11.4 28.3 14.9 60.5 ...
$ RentalAccessPath: chr "keypad" "keypad" "keypad" "keypad" ...
$ MultipleRental : logi FALSE FALSE FALSE FALSE TRUE FALSE ...
Summary Statistics
Megan Ayers
Math 141 | Spring 2026
Monday, Week 2
Summarizing Data Visually
For a quantitative variable, often want to answer:
What is an average value?
What is the trend/shape of the variable?
How much variation is there from case to case?
Need to learn key summary statistics: Numerical values computed based on the observed cases.
Measures of Center
Q: Why is the mean larger than the median?
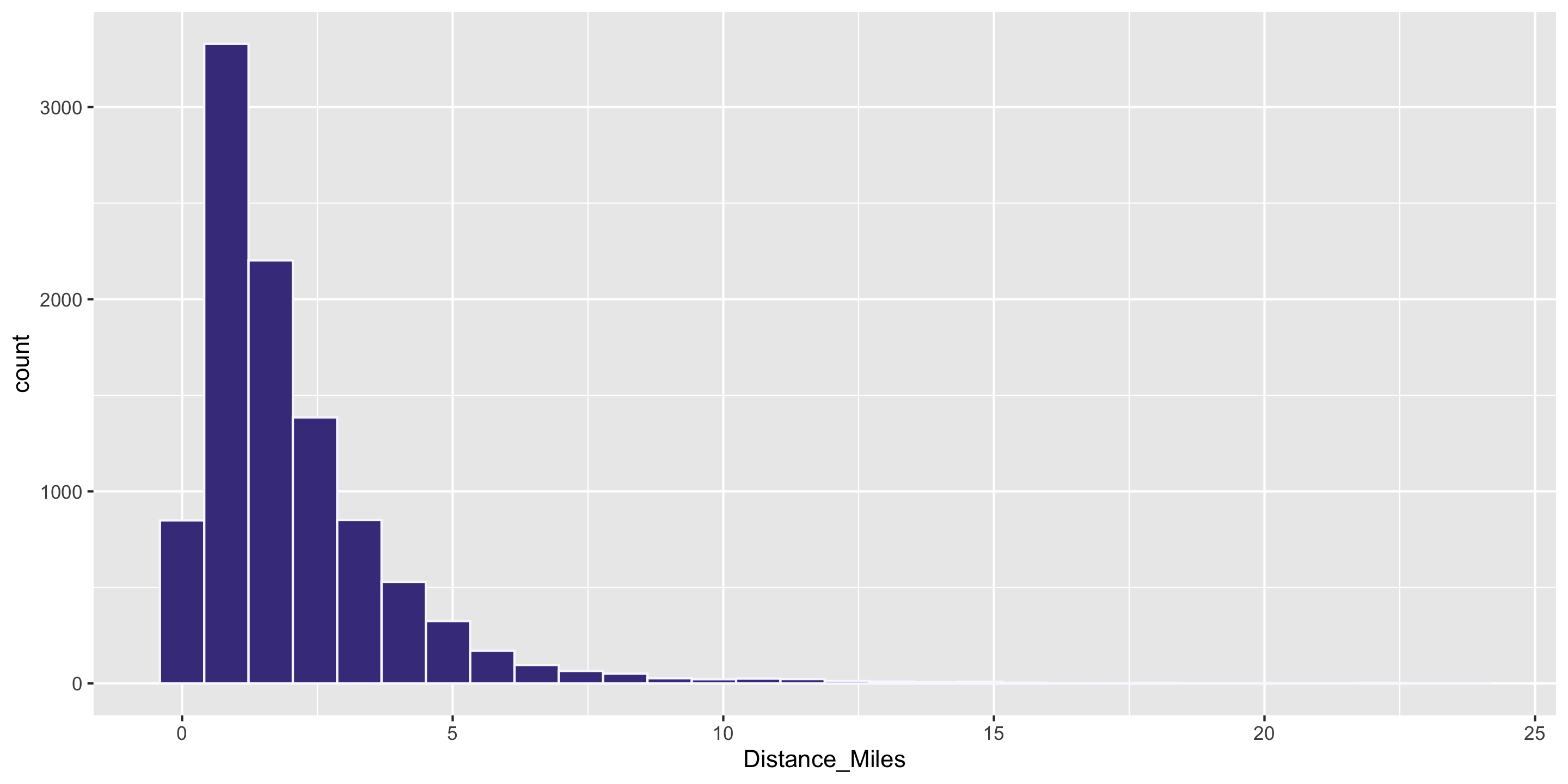
Answer: the distribution is skewed. In skewed distributions, the mean is pulled farther in the direction of skew than the median.
Computing Measures of Center by Groups
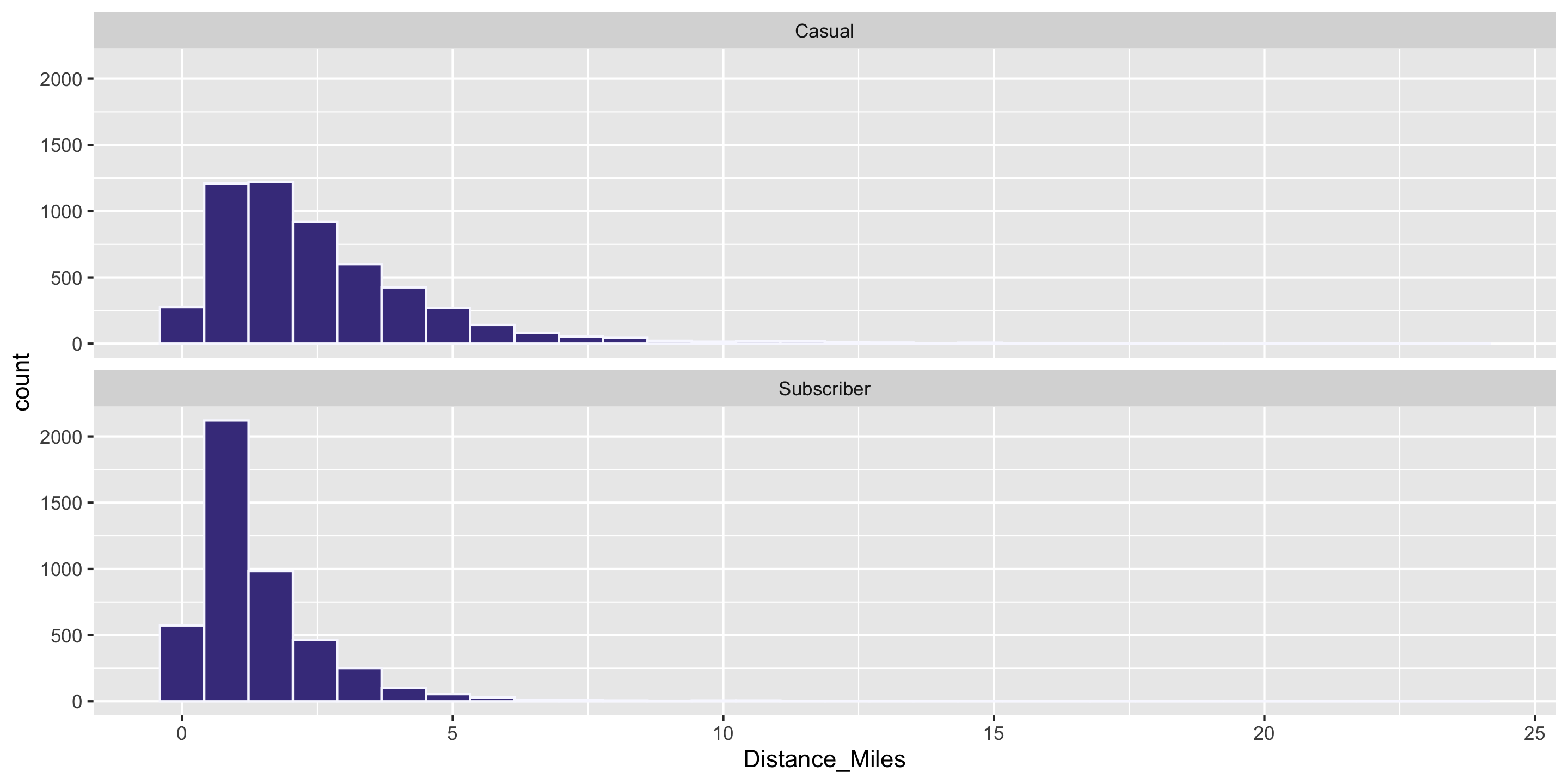
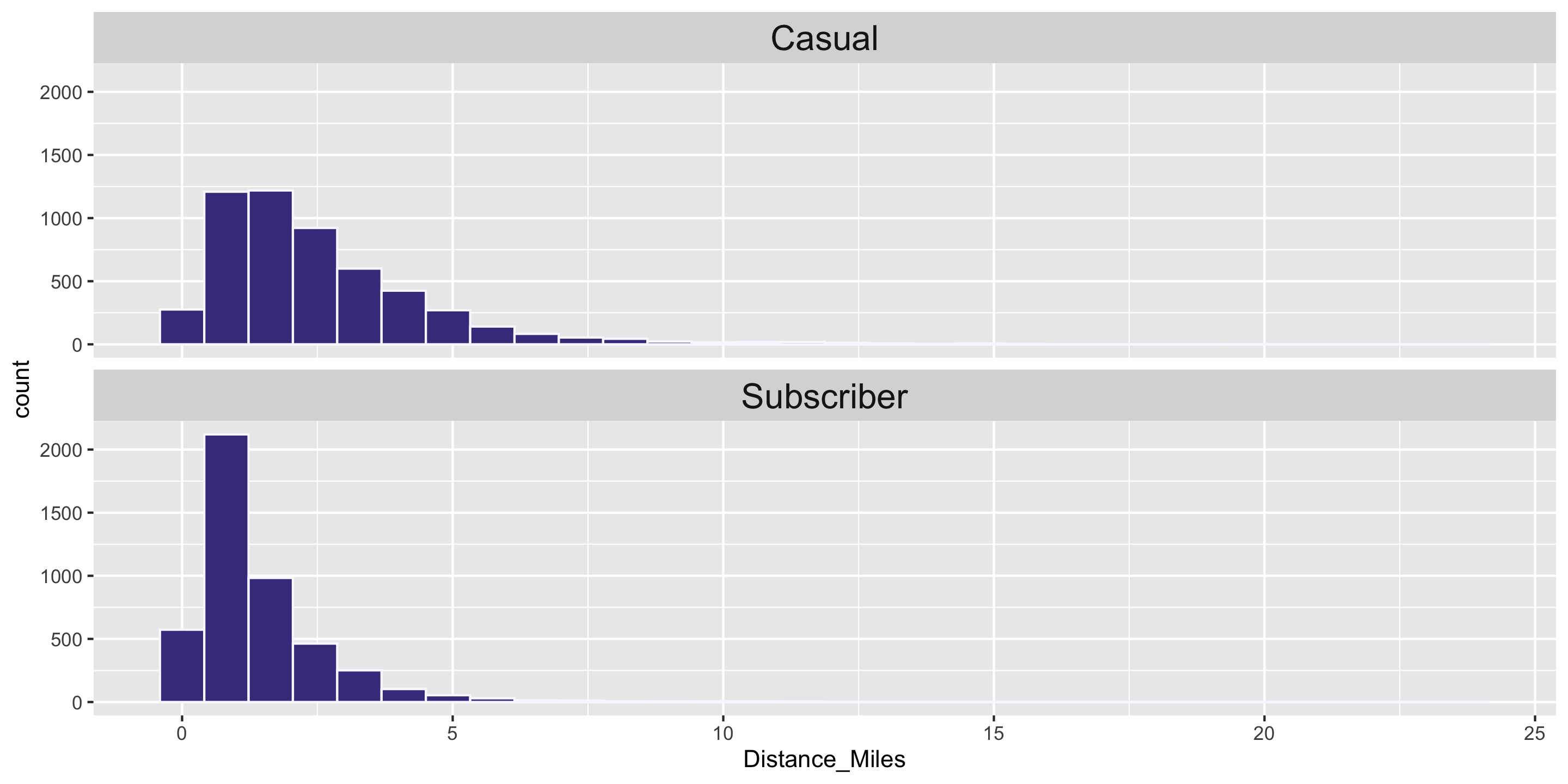
Question: Who travels further, on average? Casual biketown users or payment plan subscribers?
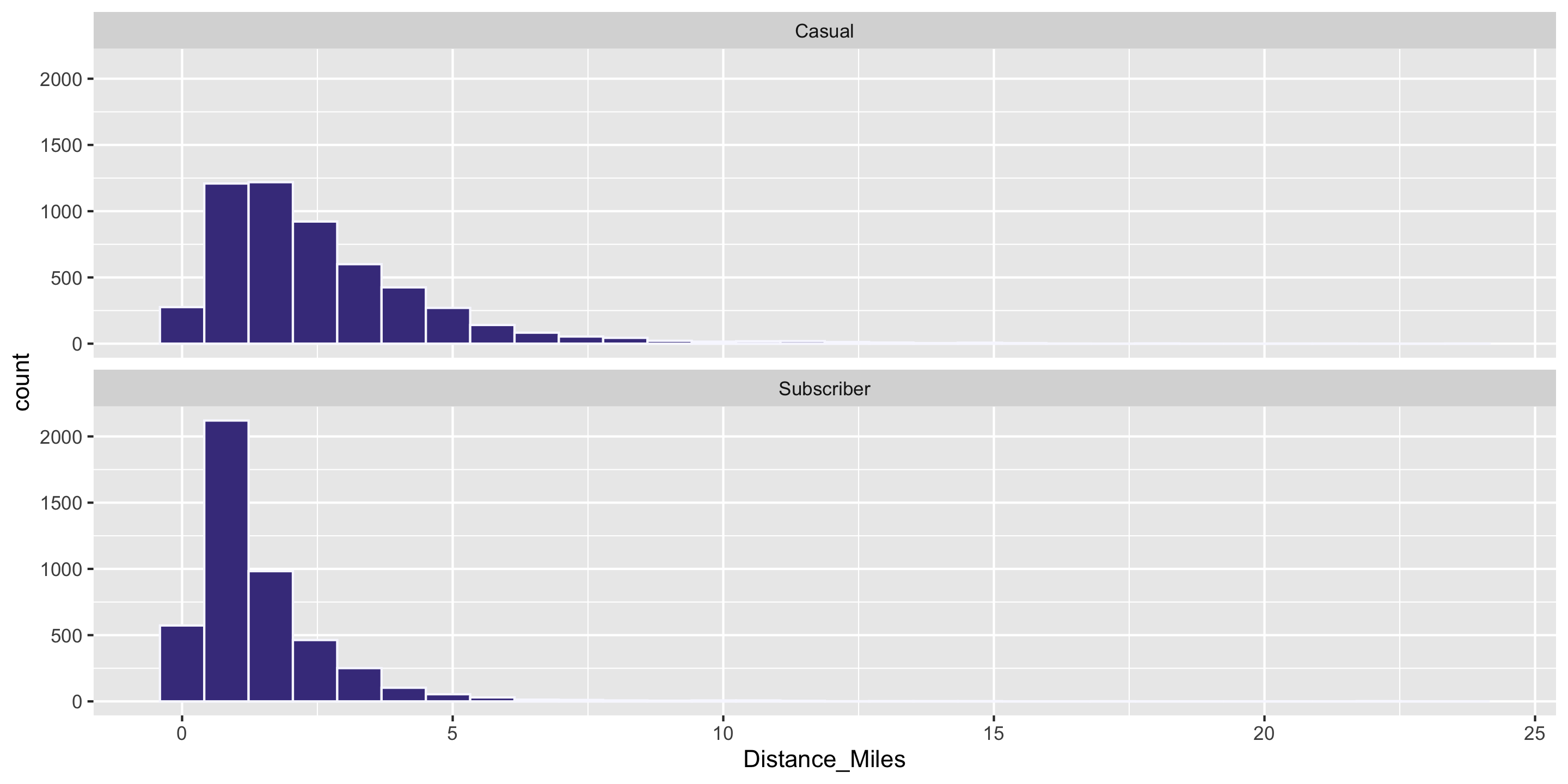
Computing Measures of Center by Groups
Handy dplyr functions that we’ll learn: group_by() and summarize().
Measures of Variability
- Want a statistic that captures how much observations deviate from the mean
- Find how much each observation deviates from the mean.
- Compute the (nearly) average of the squared deviations (\(s^2\)).
- Because observations are squared, units differ from original data.
- The square root of the sample variance is called the sample standard deviation \(s\).
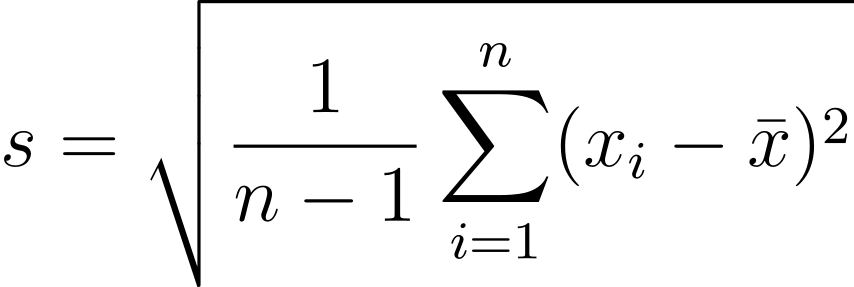
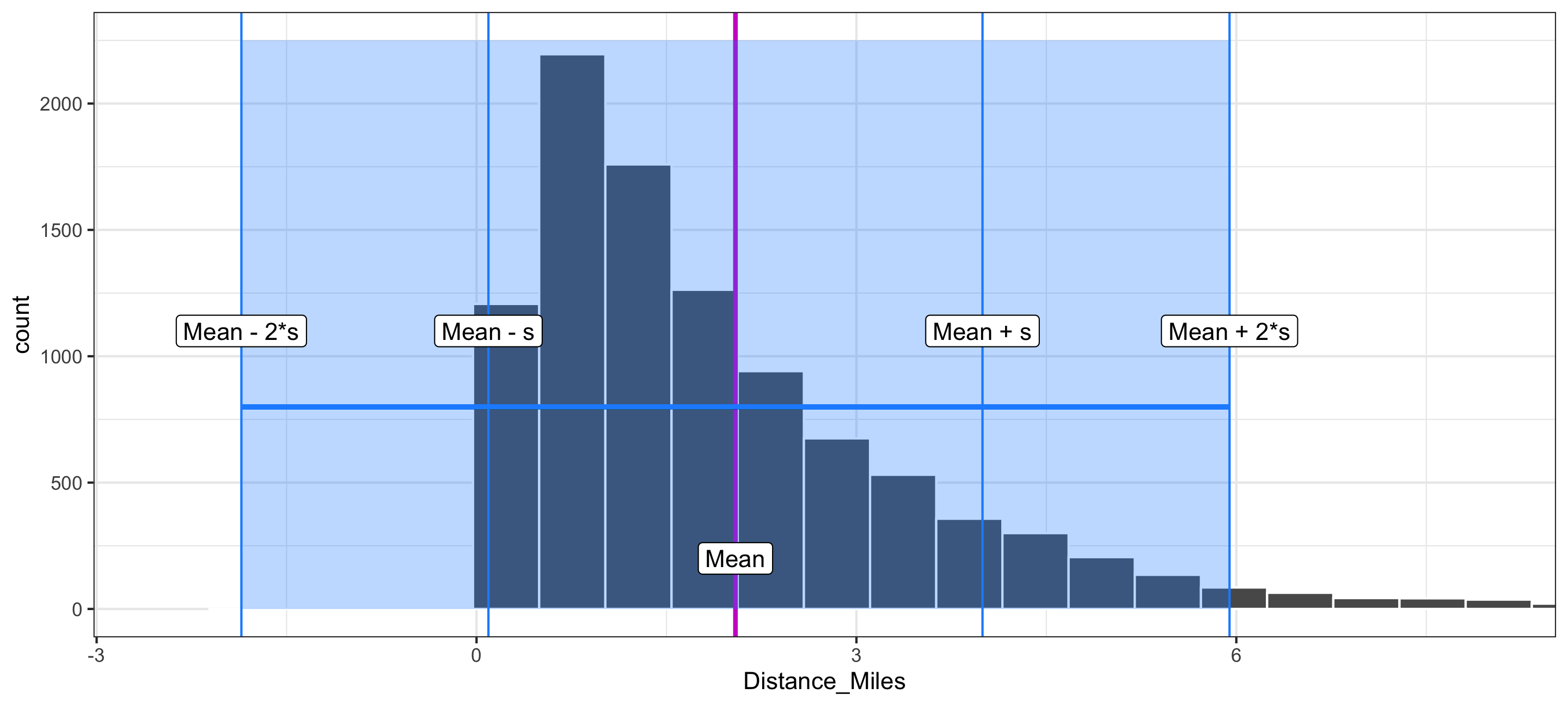
Visualizing Standard Deviation
- The standard deviation measures the typical size of deviations from the mean.
- For most data sets, the large majority of observations are within 2 standard deviations of the mean.
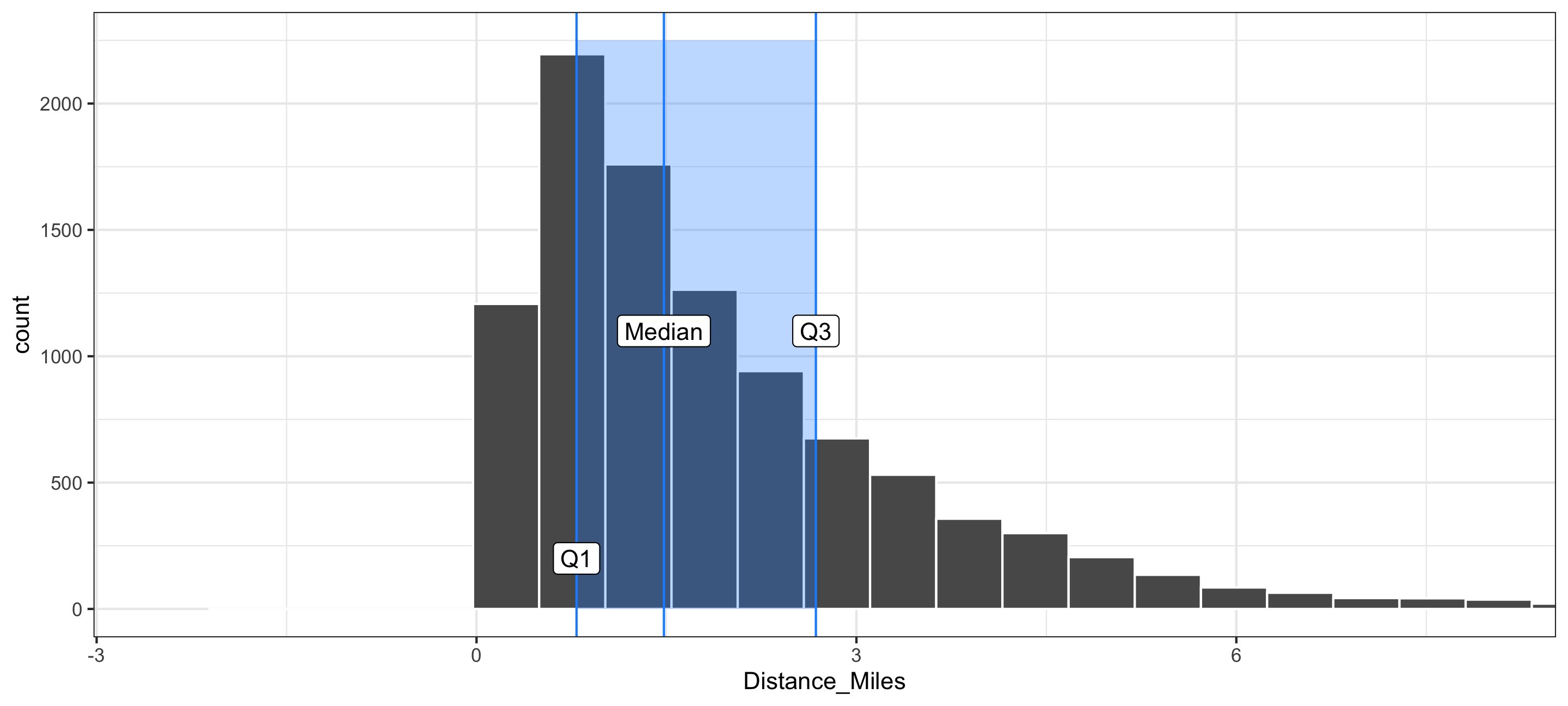
Visualizing the IQR
- In addition to the sample standard deviation and the sample variance, there is the sample interquartile range (IQR):
\[ \mbox{IQR} = \mbox{Q}_3 - \mbox{Q}_1 \]
Comparing Measures of Variability
- Q: Which is more robust to outliers, the IQR or \(s\)?
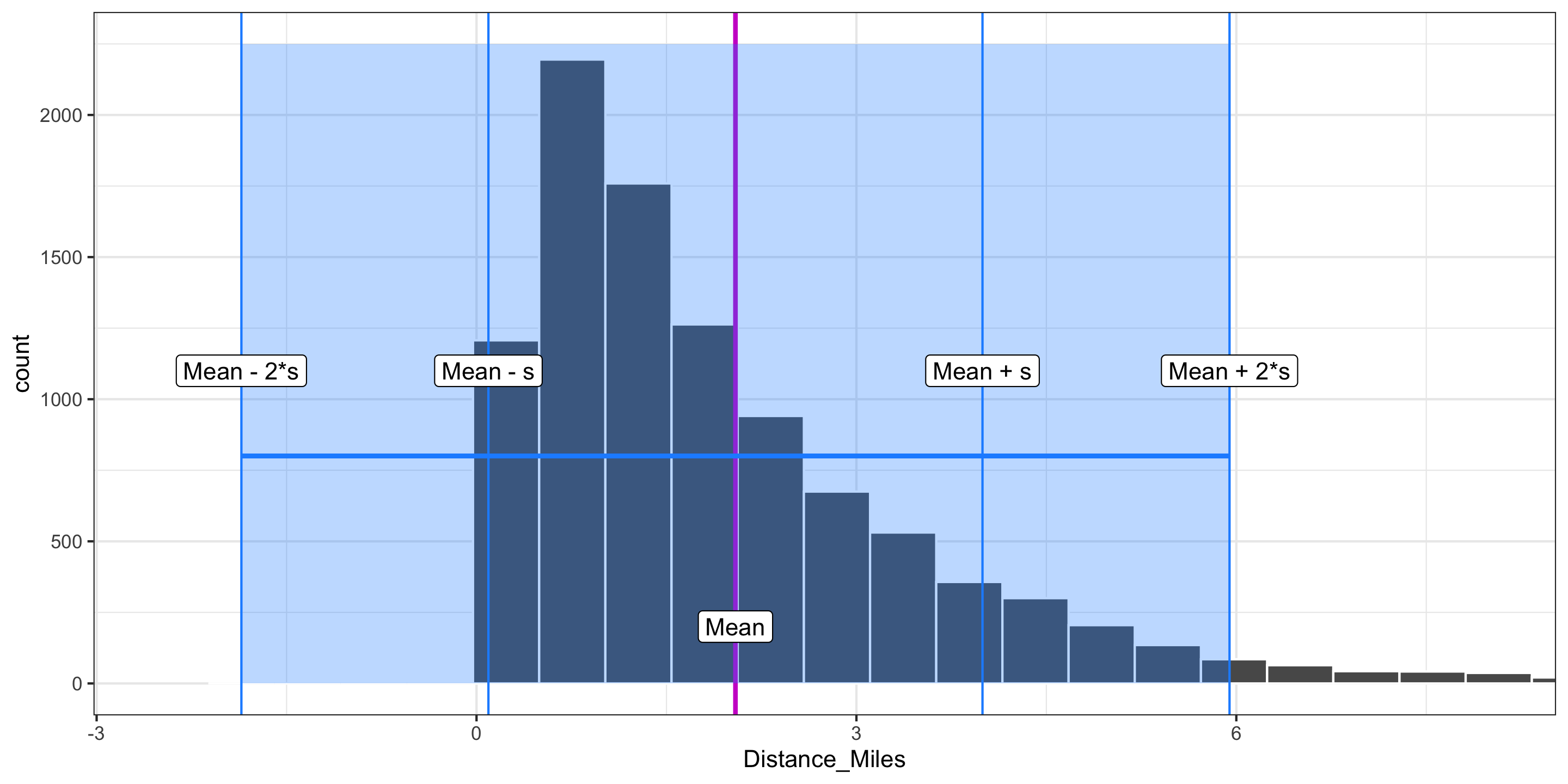
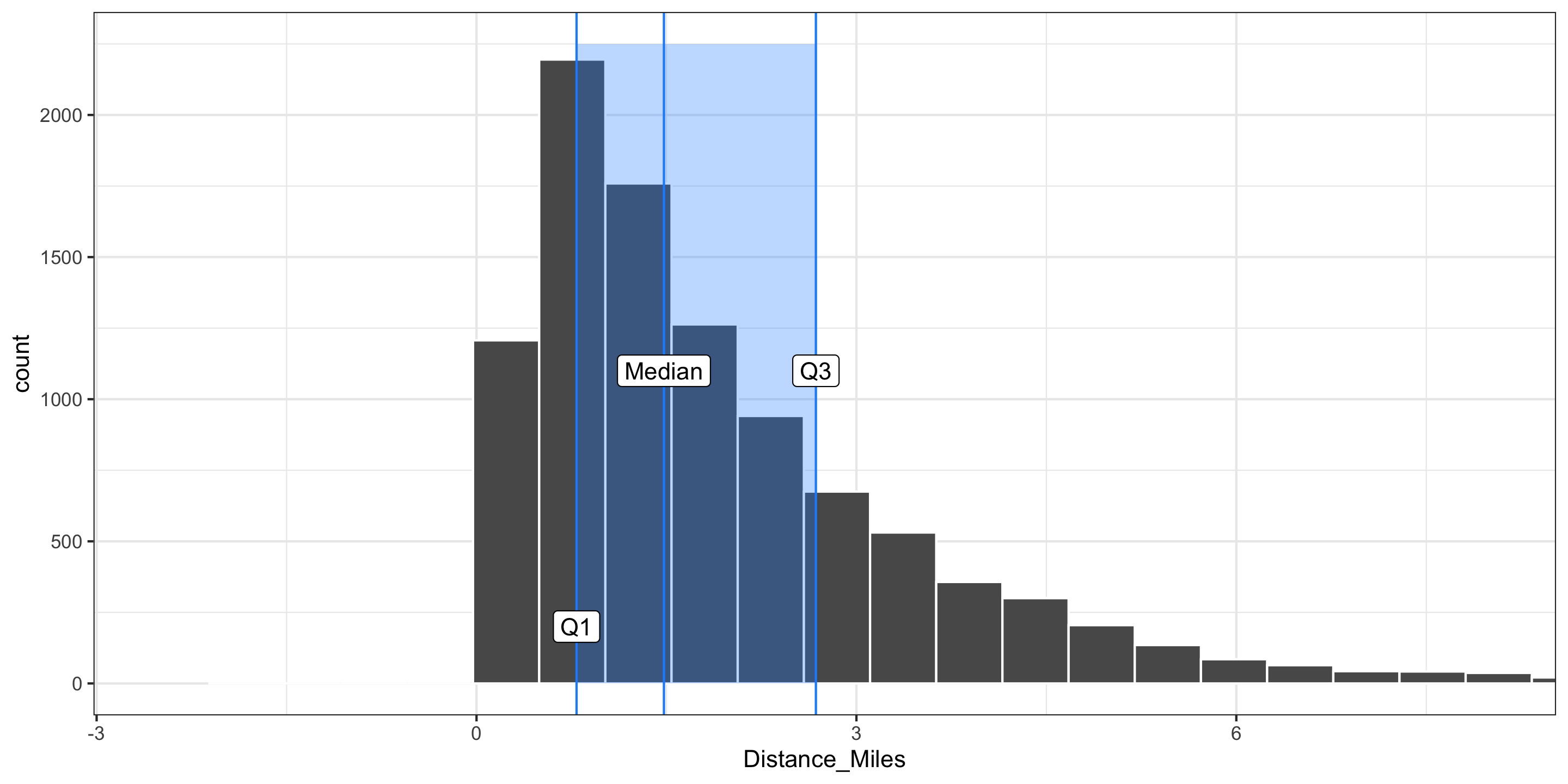
- Q: Which is more commonly used, the IQR or \(s\)?
Frequency Table
Distributions of categorical variables can be presented in tables and summarized in bar charts.
Q: Why can’t we use mean or standard deviation here?
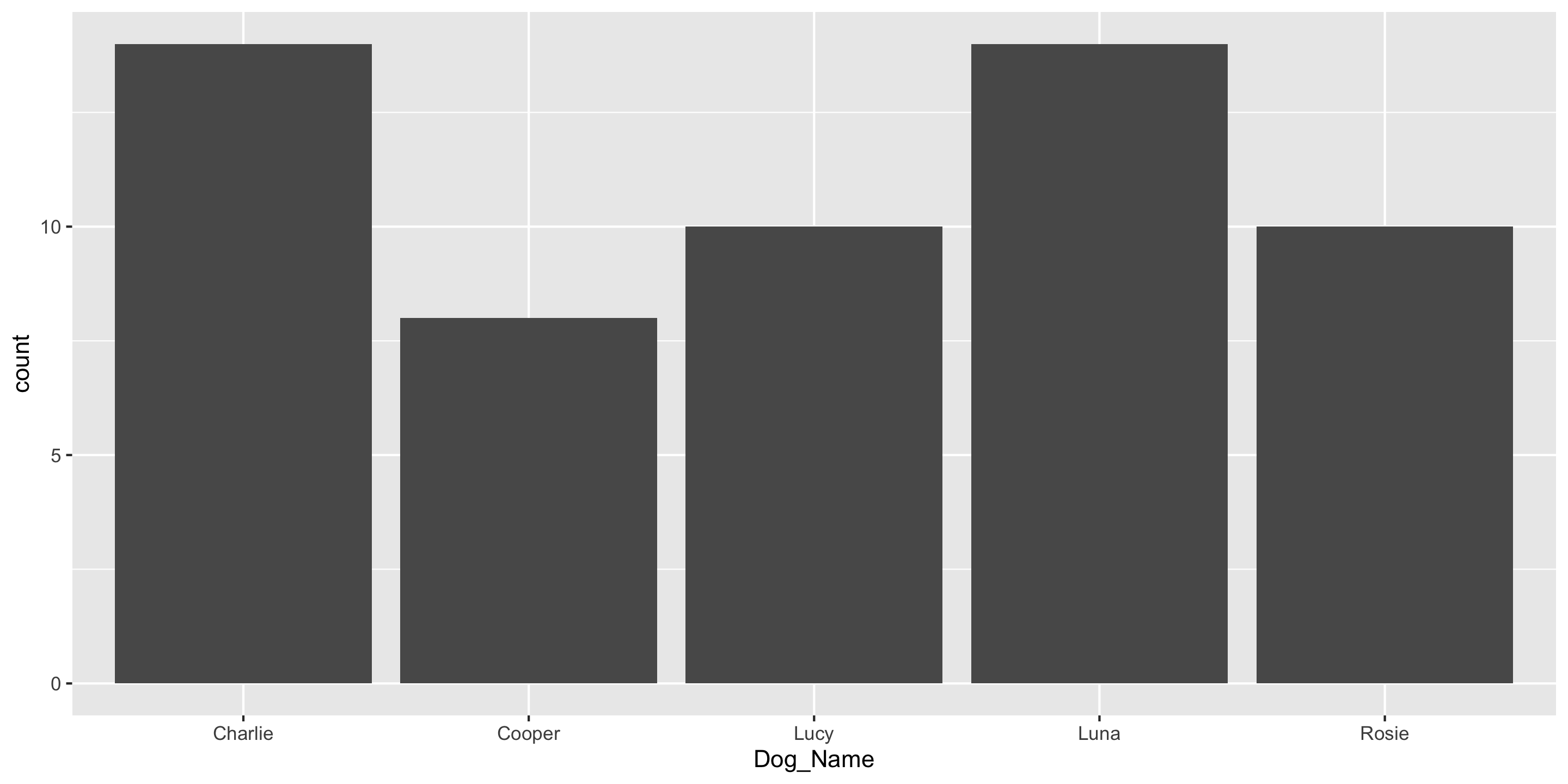
Another ggplot2 geom: geom_col()
If you have already aggregated the data, you will use geom_col() instead of geom_bar().
Dog_Name n
1 Charlie 14
2 Cooper 8
3 Lucy 10
4 Luna 14
5 Rosie 10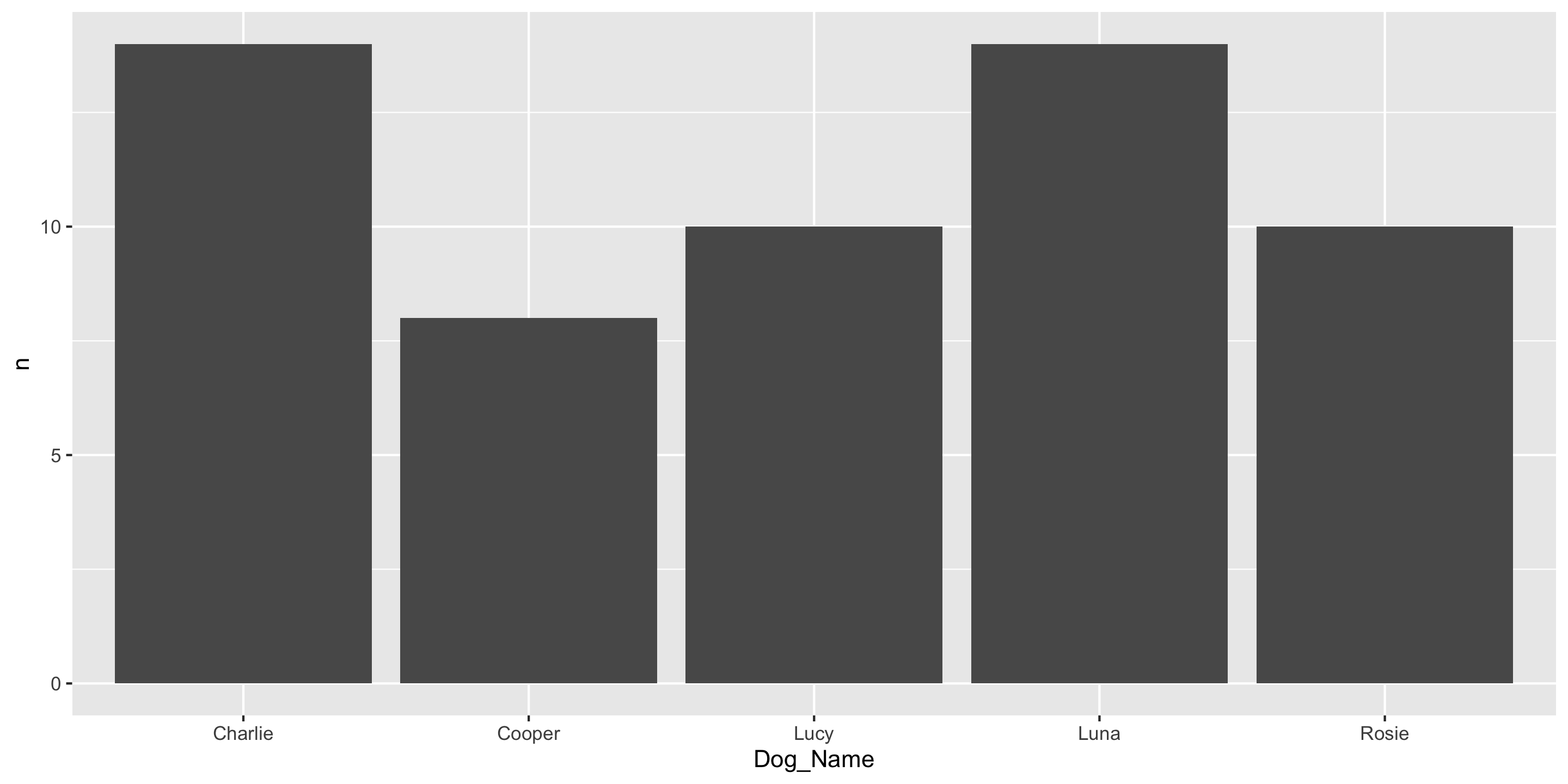
Another ggplot2 geom: geom_col()
And you can use fct_reorder to order bars by value
Dog_Name n
1 Charlie 14
2 Cooper 8
3 Lucy 10
4 Luna 14
5 Rosie 10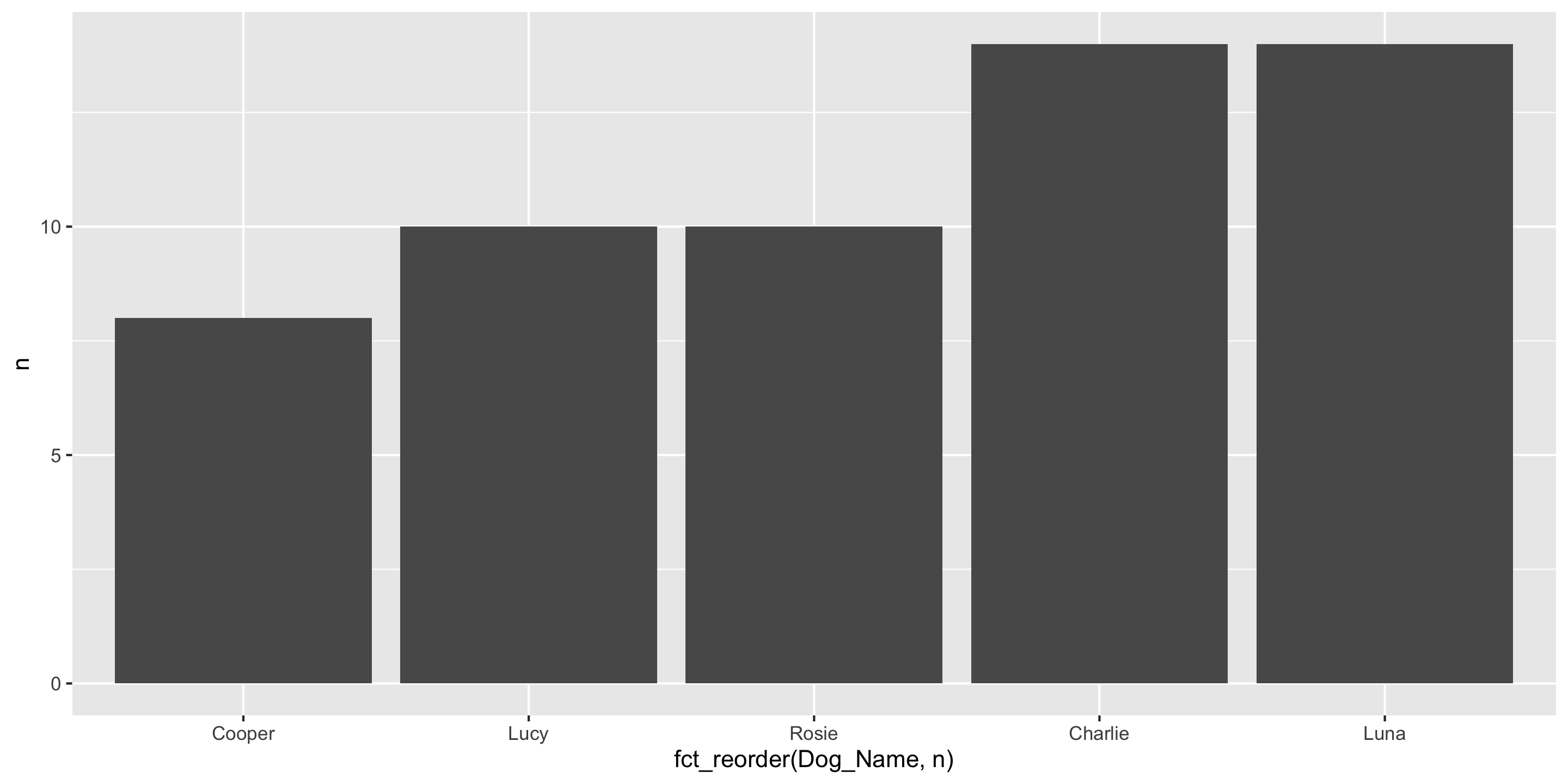
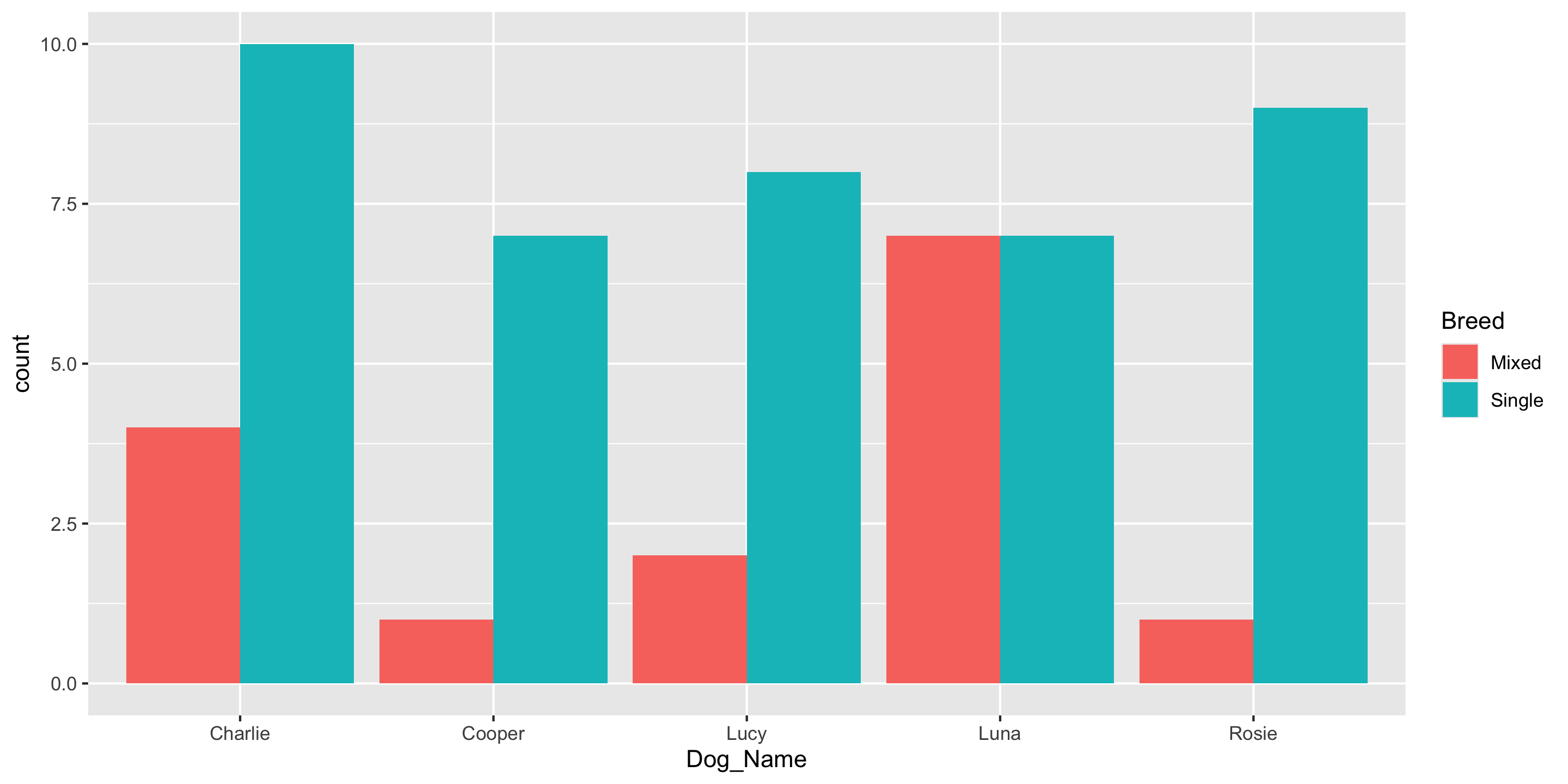
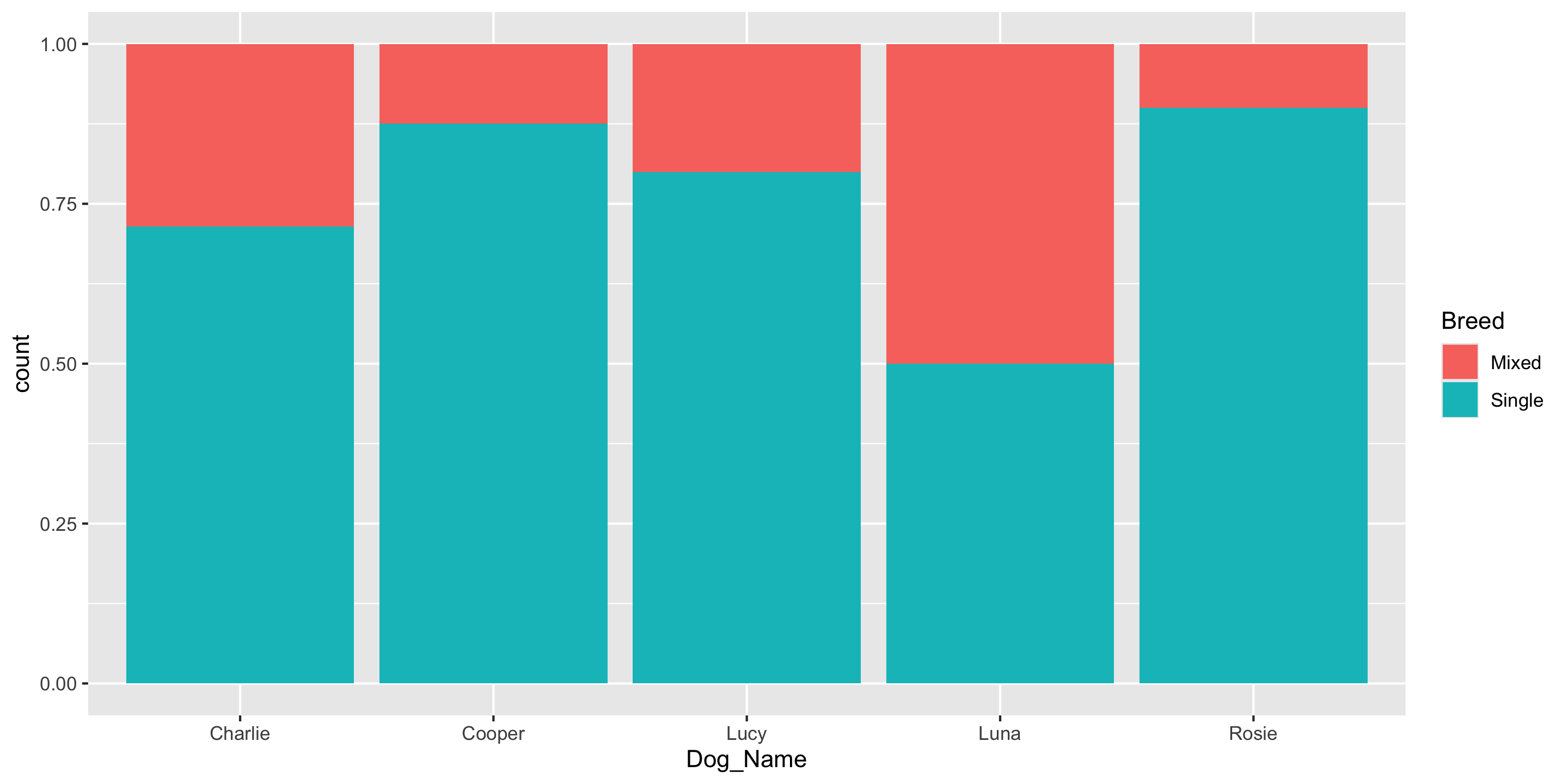
Contingency Table
To compare 2 categorical variables, we can use a contingency table
Dog_Name Breed n
1 Charlie Mixed 4
2 Charlie Single 10
3 Cooper Mixed 1
4 Cooper Single 7
5 Lucy Mixed 2
6 Lucy Single 8
7 Luna Mixed 7
8 Luna Single 7
9 Rosie Mixed 1
10 Rosie Single 9